프로그램은 실행 전 변수와 같은 기호 주소를 실제 주소로 바인딩 해야한다.
바인딩은 컴파일, 메모리 적재, 실행 시간 등에 바인딩 될 수 있다.
현재는 대부분 실행 시간에 기호 주소를 실제 주소로 바인딩한다.
컴파일, 적재 시간 바인딩과 달리 실행 시간 바인딩은 논리적 주소와 물리적 주소가 다르다.
논리적 주소와 물리적 주소는 서로 매핑되는데 이러한 매핑은 MMU(Memory Managerment Unit)에 의해 이루어진다.
동적 적재
초창기에는 모든 프로그램을 주기억장치에 적재하는 정적 적재(static loading)를 사용했다.
그런데 정적 적재는 메모리의 용량이 부족해질 수 있는 문제가 있다.
이러한 문제는 루틴이 호출될 때 해당 루틴을 주기억장치에 적재하는 동적 적재(dynamic loading)를 사용하면 해결할 수 있다.
main부터 적재 후 다른 루틴이 호출되면 해당 루틴을 적재한다.
오류 처리 루틴의 경우 사용되지 않을 수도 있는데 이러한 루틴은 적재되지 않아서 메모리 용량 문제를 어느정도 해결할 수 있다.
동적 연결
정적 연결(static linking)은 라이브러리를 프로그램과 결합하여 사용한다.
그런데 이러한 정적 연결은 라이브러리가 공유되지 않기 때문에 하드디스크와 주기억장치의 공간이 낭비된다.
그에 비해 동적 연결(dynamic linking)의 경우 각 프로그램에 stub이 존재한다.
stub은 주기억장치가 공유하는 라이브러리 루틴에서 필요한 루틴을 찾아준다.
루틴의 첫 호출은 stub이 필요하지만 그 다음은 주소 정보를 이용하기 때문에 필요없다.
이러한 방식은 라이브러리를 공유하기 때문에 공간을 절약할 수 있다.
이러한 라이브러리를 동적 연결 라이브러리(Dynamic Linking Library)라고 한다.
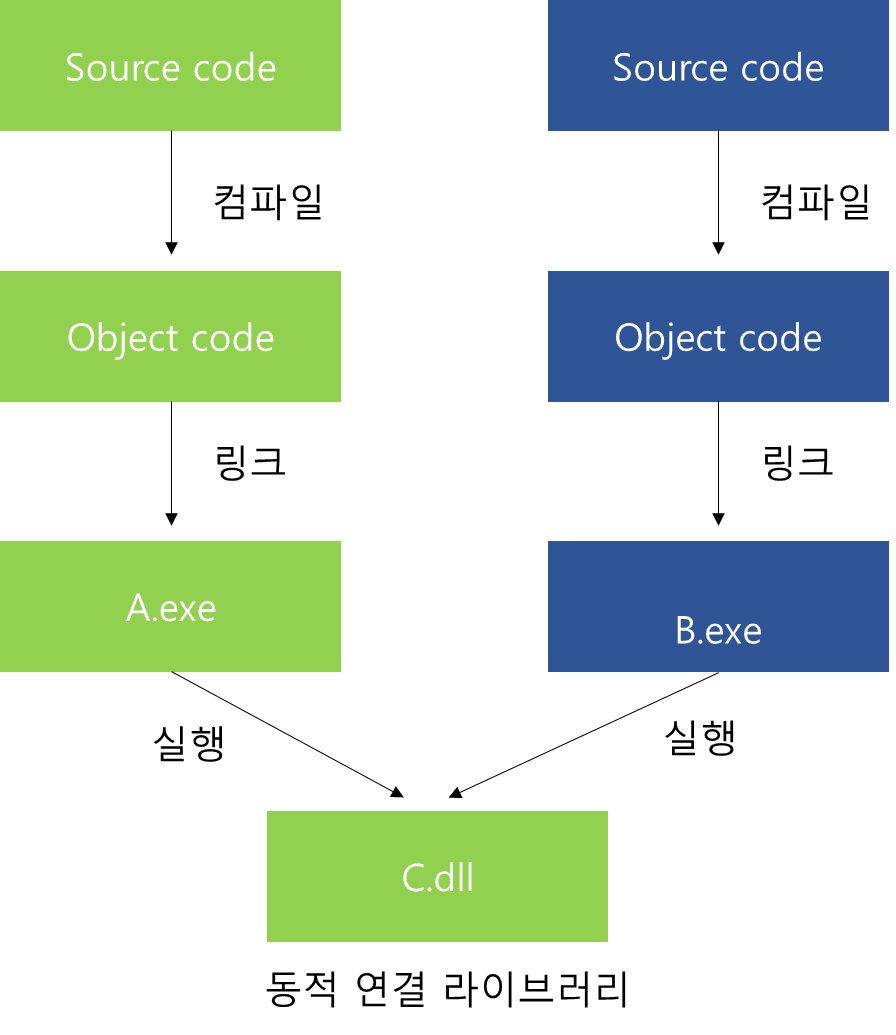
동적 연결은 라이브러리를 변경해야 할 때도 쉽게 연결할 수 있다.
그러나 다른 주소 공간에 접근해야하기 때문에 운영 체제의 도움이 필요하다.
swapping
메모리에 적재되어있는 프로세스가 많아서 용량이 부족하다면 메모리에 적재되어있는 프로세스 중 하나가 디스크로 쫓겨난다.(swap out)
그리고 나중에 다시 디스크에서 메모리로 들어오는데 (swap in) 이 과정에서 실행 시간 바인딩이라면 물리적 주소와 다른 위치로 적재될 수 있다.
연속 공간 할당
주기억장치는 운영 체제가 사용하는 영역과 유저가 사용하는 영역으로 나뉜다.
프로세스간 간섭을 막기 위해 base register와 limit register가 존재한다.
base가 a, limit이 b라고 한다면 a와 a+b 사이에 논리적 주소를 생성할 수 있다.
이러한 범위 검사를 통해 프로세스간 간섭을 막는다.
주기억장치 할당
초창기에는 주기억장치를 고정된 영역으로 분할하여 영역당 하나의 프로세스에게 할당하는 MFT 방식을 사용했다.
그런데 이 방식은 메모리를 프로세스의 크기에 맞게 정확히 분할하기 어렵기 때문에 내부 단편화(internal fragmentation) 문제가 발생한다.

MVT 방식의 경우 사용 중인 공간과 사용하지 않는 공간으로 구분하여 사용하지 않으면서 사용 가능한 공간(hole) 중 프로세스를 수용 가능한 공간을 찾아서 프로세스를 할당한다.

그런데 적합한 hole들이 여러 개 있을텐데 hole을 찾는 알고리즘은 크게 3가지가 존재한다.
- 최초 적합(first fit) : 가장 처음 발견한 적합한 hole에 할당한다.
- 최적 적합(best fit) : 적합한 hole들 중 가장 작은 hole에 할당한다.
- 최악 적합(worst fit) : 적합한 hole들 중 가장 큰 hole에 할당한다.
위 3가지는 모두 외부 단편화(external fragmentation) 문제가 존재한다.
외부 단편화 문제는 다음과 같이 hole들을 전부 합치면 프로세스가 들어갈 공간이 생기는데 연속되지 않아서 프로세스가 할당되지 못하는 문제를 의미한다.

compaction을 통해서 적재 중인 프로세스들을 재배치를 하여 해결할 수 있지만 오버헤드가 크다.
페이징
지금까지는 프로세스에게 공간을 할당해주려면 연속된 공간을 할당해줘야했다.
그러나 페이징 기법을 사용하면 연속한 공간을 할당할 필요가 없다.
먼저 물리적인 기억 장치를 고정된 크기의 프레임(frame)으로 나누고 논리적 주소 공간도 같은 크기의 페이지(page)로 나눈다.
페이지는 어떤 프레임과도 매핑될 수 있다.
그런데 연속된 공간을 할당하지 않으면 프로세스가 제대로 동작하기 어려울 것이다.
그래서 MMU의 페이지 테이블을 사용한다.

실제 메모리에 프로세스는 여러 프레임에 나뉘어 저장되어 있지만 페이지 테이블의 페이지는 연속이라 CPU는 연속적이라고 인식하는 것이다.
운영 체제는 프레임 테이블과 페이지 테이블을 유지한다.
프레임 테이블에는 프레임의 할당 여부, 매핑되어있는 페이지와 같은 정보가 담겨있고
페이지 테이블에는 프레임 매핑정보가 담겨있다.
프로세스마다 페이지 테이블을 유지해야 하는데 이 페이지 테이블은 보통 PCB 내부에 존재한다.
이 페이지 테이블로 인해 context switching의 시간이 늘어날 수 있다.
페이징을 사용하면 외부 단편화 문제는 발생하지 않으나 내부 단편화 문제는 발생할 수 있다.
내부 단편화 문제가 발생한다면 마지막 페이지에서 발생할 것이다.
그런데 애초에 페이지의 크기는 작아서 마지막 페이지에서 내부 단편화 문제가 발생하더라도 그 크기는 무시할 만하다.
페이지 테이블 하드웨어 구현
하드웨어에서 페이지 테이블을 구현하는 방법은 여러가지가 있다.
먼저 cpu의 전용 레지스터 집합을 사용하는 방법이다. cpu 내부의 레지스터이기 때문에 속도가 빠르지만 페이지 테이블의 크기가 작을 때만 사용할 수 있다.
그 다음은 주기억장치에 페이지 테이블을 저장하는 방식이다.
주기억장치에 페이지 테이블을 저장하고 레지스터에는 이 페이지 테이블을 가리키는 주소만 저장한다.
이 레지스터는 PTBR이라고 한다.
페이지 테이블의 크기 제한의 부담은 없어졌지만 주기억장치에 접근하기 위해 항상 두 번의 접근을 해야하기 때문에 속도가 느리다.
또 다른 방법은 전용 캐시를 사용하는 방법이다.
전용 캐시는 TLB라고 하며 페이지 테이블의 일부만 가지고 있다.
캐시의 기능을 하기 때문에 먼저 TLB를 검색해서 페이지가 없다면 주기억장치의 페이지 테이블을 참조한다.
보호와 공유
페이징 기법에서 보호를 하기 위해 보호 비트를 사용한다.
r(read), w(write), x(execute) 비트를 통해 접근을 제한할 수 있다.
또한 페이징 기법을 사용하면 공통 코드를 공유할 수 있다.
150kb의 코드와 50kb의 데이터 공간이 필요하다면 150kb의 코드가 수행시간 동안 변경되지 않는다는 가정 하에 150kb의 코드를 공유할 수 있다.
세그먼테이션
세그먼테이션 기법은 페이징 기법과 유사하지만 다르다.
페이징과 다르게 주기억장치를 순서가 없는 다양한 크기의 세그먼트 집합으로 본다.
페이징은 고정된 크기의 페이지로 나누어져 있지만 세그먼테이션은 가변적인 크기의 세그먼트로 나누어져 있다.

물리적으로 분할한 페이징과 다르게 세그먼테이션은 논리적인 분할이기 때문에 보호를 정의하기 상대적으로 쉽다.
또한 세그먼테이션은 외부 단편화 문제가 발생할 수 있다.
'공부 > OS' 카테고리의 다른 글
| [OS] 운영체제 system call (0) | 2024.08.25 |
|---|---|
| [OS] 교착 상태 (deadlock) (0) | 2023.06.19 |
| [OS] CPU scheduling 알고리즘 (0) | 2023.06.11 |
| [OS] 프로세스 동기화 문제 (세마포어) (0) | 2023.05.27 |
| [OS] 쓰레드의 개념과 프로세스와의 차이 (0) | 2023.05.25 |