개요
https://growth-coder.tistory.com/328
[Node.js] HTTP POST로 SSE 구현하기 + nginx buffering 문제 해결
개요저희 프로젝트는 LangChain을 활용하여 AI 응답을 반환하는 API를 만들어서 사용하고 있습니다. AI가 생성한 응답을 그대로 HTTP 응답으로 반환해주는 API입니다. 하지만 이러한 형태는 AI의 응답
growth-coder.tistory.com
이전 포스팅에서 스트리밍 기능을 통해 chunk 단위로 클라이언트에게 보내주는 기능을 구현했습니다.
사용성 향상을 위해 응답을 중간에 멈추는 기능을 개발하려고 합니다.
가장 쉬운 방법은 단순하게 클라이언트에서 응답을 멈추는 버튼을 클릭하면 출력을 멈추는 방법입니다.
하지만 이 방법은 LLM 응답 자체를 멈추지 않습니다.
LLM은 응답을 계속 생성하여 클라이언트에게 보내주지만 클라이언트에서 정지 버튼을 누른 시점 이후 chunk를 출력하지 않기 때문입니다.
결국 정지 버튼을 누르더라도 token 사용량 자체가 줄어들지 않고 LLM이 생성한 전체 응답에 대한 token이 사용됩니다.
실제로 저희가 받은 chunk보다 더 많은 token을 사용하게 되는 것입니다.
저희가 원하는 기능은 스트리밍 중간에 정지 버튼을 눌렀을 때 LLM의 응답을 중단하고 그 시점까지 받은 응답에 대한 토큰만 사용하여 추가 요금이 부과되지 않도록 하는 것입니다.
즉, LLM이 chunk 단위로 주는 응답 자체를 중간에 끊는 기능이 필요합니다.
본격적인 포스팅에 앞서 상단의 포스팅을 보고 오는 것을 추천드립니다.
AbortController
브라우저와 node.js 모두 AbortController를 통해 보낸 웹 요청을 중간에 취소할 수 있습니다.
AbortController로 OpenAI API 요청을 보낸 후 AbortController로 요청을 취소하면 LLM의 응답을 중단할 수 있습니다.
저희 프로젝트에서 OpenAI API를 사용하는 주체는 서버이기 때문에 서버에서 AbortController를 사용하면 됩니다.
AbortController의 간단한 사용 방법은 다음과 같습니다.
DOM 요청과 통신하거나 취소하는데 사용되는 AbortSignal 객체를 생성해서 웹 요청을 보낼 때 AbortSignal 객체를 연결해주면 됩니다.
그리고 AbortController의 abort 메소드를 호출하면 웹 요청을 중단할 수 있습니다.
var controller = new AbortController();
var signal = controller.signal;
var downloadBtn = document.querySelector('.download');
var abortBtn = document.querySelector('.abort');
downloadBtn.addEventListener('click', fetchVideo);
abortBtn.addEventListener('click', function() {
controller.abort();
console.log('Download aborted');
});
function fetchVideo() {
...
fetch(url, {signal}).then(function(response) {
...
}).catch(function(e) {
reports.textContent = 'Download error: ' + e.message;
})
}
AbortController 자세한 사용 방법은 아래 링크에서 확인하실 수 있습니다.
https://developer.mozilla.org/ko/docs/Web/API/AbortController
AbortController - Web API | MDN
AbortController 인터페이스는 하나 이상의 웹 요청을 취소할 수 있게 해준다.
developer.mozilla.org
그러면 간단하게 node.js 기반 express를 통해 LLM 스트리밍 응답을 끊어봅시다.
먼저 패키지를 설치합니다.
yarn add express @langchain/openai @langchain/core
ChatOpenAI model을 생성합니다.
const model = new ChatOpenAI({
streaming: true,
modelName: "gpt-4o-mini",
temperature: 0.7,
});
그리고 스트리밍을 시작할 때 AbortController의 AbortSignal을 연결해주면 됩니다.
const controller = new AbortController();
const stream = await model.stream(
"LangChain Express 스트리밍 테스트하는 방법 알려줘",
{
signal: controller.signal,
}
);
중단하고 싶을 때는 AbortController 인스턴스의 abort 메소드를 호출하면 됩니다.
controller.abort();
abort 메소드를 호출하면 AbortError가 발생되기 때문에 AbortError를 잘 catch해서 처리해줘야 합니다.
또한 클라이언트에게 text/event-stream 방식으로 보내주고 있었다면 abort 메소드 호출 후 response도 잘 종료해줘야 합니다.
그러면 이제 express로 서버를 띄우고 2초 뒤에 강제로 요청을 중단하는 API를 작성해봅시다.
import express from "express";
import { ChatOpenAI } from "@langchain/openai";
const app = express();
const PORT = 3000;
const model = new ChatOpenAI({
streaming: true,
modelName: "gpt-4o-mini",
temperature: 0.7,
});
app.get("/chat", async (req, res) => {
res.setHeader("Content-Type", "text/plain");
const controller = new AbortController();
const startTime = Date.now();
let isClosed = false;
try {
const stream = await model.stream(
"LangChain Express 스트리밍 테스트하는 방법 알려줘",
{
signal: controller.signal,
}
);
for await (const chunk of stream) {
if (isClosed) break; // 응답이 이미 종료되었으면 더 이상 처리하지 않음
res.write(chunk.content); // 클라이언트에 실시간 전송
process.stdout.write(chunk.content);
// 2초 후 강제 중단
if (Date.now() - startTime > 2000) {
controller.abort();
if (!isClosed) {
res.end(); // 응답 종료
isClosed = true; // 응답이 종료되었음을 표시
}
}
}
if (!isClosed) {
res.end(); // 스트리밍 종료
isClosed = true; // 응답이 종료되었음을 표시
}
} catch (error) {
if (error.name === "AbortError") {
console.log("스트리밍 중단");
} else {
console.error("오류 발생:", error);
}
if (!isClosed) {
res.status(500).send("서버 오류");
isClosed = true;
}
}
});
app.listen(PORT, () => console.log(`서버 실행 중: http://localhost:${PORT}`));
위 코드를 실행하기 위해서는 환경 변수에 유효한 OPENAI_API_KEY가 등록되어 있어야 합니다.
서버를 실행 후 http://localhost:3000/chat으로 GET 요청을 보내보시면 2초 뒤 응답이 중단되는 모습을 확인하실 수 있습니다.
한 번 token 사용량도 줄어들었는지 확인해봅시다.
<중단 없이 모든 응답을 스트리밍으로 받았을 때 token 사용량>
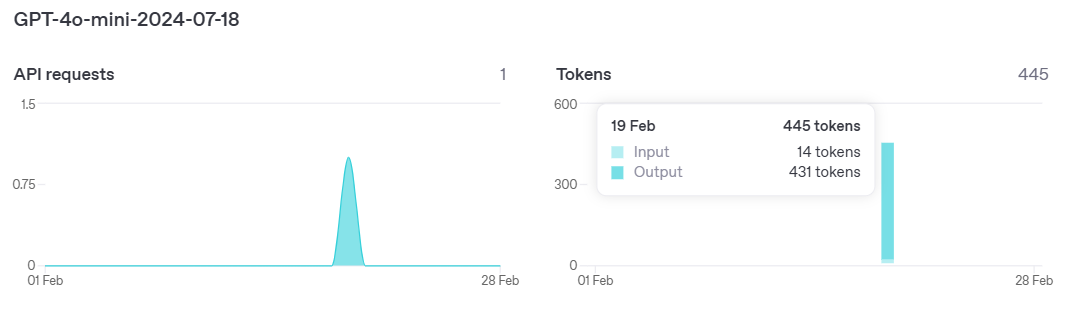
input 14, output 431개의 토큰이 사용되었습니다.
<2초 뒤에 요청을 강제로 중단했을 때 token 사용량>

OpenAI platform에서는 각 API 요청마다 token usage를 확인할 수 없으니 이전 token 사용량을 보면서 두 번째 요청에 대한 token 사용량을 계산해봅시다.
input token은 똑같이 14개가 사용되었고 output token은 118개가 사용되었습니다.
AbortController로 요청을 중간에 중단했더니 지금까지 받은 응답에 대한 token만 사용한 모습을 확인할 수 있습니다.