개요
지금까지 개발한 추천 API의 흐름은 다음과 같습니다.

- 사용자의 자연어 요청이 API를 통해 들어옵니다. (공덕에서 여자친구와 1주년 기념일에 갈 만한 식당 추천해줘)
- OpenAI API를 사용해서 위치 정보를 추출하고 요청을 벡터로 변환합니다.
- 2번에서 추출한 위치 정보를 기반으로 Kakao Map API를 호출하여 위도, 경도를 구합니다.
- Query를 통해 위도, 경도로 식당을 필터링하고 2번에서 변환한 벡터로 cosine 유사도 검색을 수행합니다.
- 메타데이터가 포함되지 않은 PK 리스트를 받습니다.
- 식당 서버의 메타데이터 API를 호출하여 메타 데이터를 받습니다.
- 조합하여 최종적으로 사용자에게 응답을 내려줍니다.
벡터 변환 과정은 조금 더 복잡하지만 해당 내용이 이번 포스팅의 핵심이 아니기 때문에 생략했습니다.
벡터 변환 과정은 실제로 4가지 카테고리로 나눈 뒤, 벡터로 변환하는 과정이 포함되어 있는데 궁금하신 분들은 아래 포스팅을 확인해보시면 좋을 것 같습니다.
https://growth-coder.tistory.com/358
식당 추천 시스템 개발기 #3 - 식당 추천 원리
개요 이번에 "현재 자신의 상황에 맞는 식당 추천 시스템"을 개발하면서 식당 정보와 사용자들의 리뷰 정보를 수집하는 크롤링 코드를 작성했습니다. 이제 이 리뷰 정보를 기반으로 사용자들이
growth-coder.tistory.com
기존의 추천 API의 흐름을 보면 외부 API의 호출이 꽤나 많습니다.
OpenAI API도 호출하고, Kakao Map API도 호출하고 식당 서버 API도 호출합니다.
즉, 네트워크 I/O 대기 시간이 API의 대부분을 차지합니다.
성능을 개선하기 위해 저는 로컬 캐시를 도입해서 외부 API의 응답을 캐싱해두기로 결정했습니다.
캐싱 대상 데이터 선정
먼저 어떠한 API의 응답을 캐싱 할지 결정해야 합니다.
변경이 잦지 않고 자주 참조되는 데이터를 캐싱하는 것이 좋습니다.
이러한 점에서 Kakao Map API와 식당 서버 API 응답을 캐싱하기로 결정했습니다.
우선 Kakao Map API는 지역 명을 요청으로 넣고 위도, 경도를 반환받기 때문에 해당 데이터의 변경은 거의 없을 것이라고 판단했습니다.
식당 서버 API도 마찬가지 입니다. PK를 요청으로 넣고 식당 메타데이터를 반환받습니다.
식당 메타데이터는 위도, 경도에 비해서 변경이 발생할 가능성이 높으나 역시 변경은 거의 없을 것이라고 판단했습니다.
OpenAI API는 캐싱하지 않기로 결정했습니다.
사용자의 자연어 요청이기 때문에 같은 요구를 하더라도 요청 형태가 다를 수 있습니다.
"공덕에서 중국집 추천", "공덕 중국집 추천해줘", "공덕 중식 추천"
이러한 요청을 모두 캐싱하게 될 경우 메모리는 많이 차지하면서 cache hit 비율이 낮을 것이라고 판단했습니다.
AOP를 활용한 로컬 캐시
spring은 캐시 추상화 계층을 제공하고 있으며 AOP 방식으로 쉽게 캐시를 적용할 수 있습니다.
먼저 @EnableCaching으로 캐싱을 활성화합니다.
@SpringBootApplication
@EnableCaching
public class WellMeetRecommendationApplication {
public static void main(String[] args) {
SpringApplication.run(WellMeetRecommendationApplication.class, args);
}
}
다음으로 여러 캐시를 쉽게 등록하기 위해 Enum으로 지정합니다.
@Getter
public enum CacheType {
RESTAURANT("restaurant", 10, 10000),
LOCATION("location", 10, 10000);
CacheType(String cacheName, int expiredAfterWrite, int maximumSize){
this.cacheName = cacheName;
this.expiredAfterWrite = expiredAfterWrite;
this.maximumSize = maximumSize;
}
private String cacheName;
private int expiredAfterWrite;
private int maximumSize;
}
식당 정보 API를 캐싱할 restaurant와 Kakao Map API를 캐싱할 location 타입을 생성했습니다.
configuration을 통해 캐시 매니저를 등록합니다.
@Configuration
public class CacheConfig {
@Bean
public CacheManager cacheManager(){
List<CaffeineCache> caches = Arrays.stream(CacheType.values())
.map(cache -> new CaffeineCache(cache.getCacheName(), Caffeine.newBuilder().recordStats()
.expireAfterWrite(cache.getExpiredAfterWrite(), TimeUnit.SECONDS)
.maximumSize(cache.getMaximumSize())
.build()
)
)
.collect(Collectors.toList());
SimpleCacheManager cacheManager = new SimpleCacheManager();
cacheManager.setCaches(caches);
return cacheManager;
}
}
생성한 CacheType의 모든 타입을 캐시로 만들어서 캐시 리스트를 cache manager에 등록합니다.
이제 API를 호출해서 응답을 반환하는 메소드에 @Cacheable 어노테이션을 붙이면 됩니다.
value에는 cache manager에 등록한 cache name을 붙이면 됩니다.
다음 코드는 식당 메타데이터 API 호출해서 반환하는 메소드에 캐싱을 적용한 코드입니다.
@Component
public class RestaurantClient {
private final RestClient restClient;
private final String restaurantUrl;
public RestaurantClient(RestClient restClient, @Value("${services.restaurant.url}") String restaurantUrl) {
this.restClient = restClient;
this.restaurantUrl = restaurantUrl;
}
@Cacheable(value = "restaurant")
public RestaurantDetailResponse getRestaurantById(String restaurantId) {
return restClient.get()
.uri(restaurantUrl + "/user/restaurant/{id}?memberId=1", restaurantId)
.retrieve()
.onStatus(status -> status.value() == 404,
(request, response) -> {
throw new WellMeetException(ErrorCode.RESTAURANT_NOT_FOUND);
})
.onStatus(status -> status.is5xxServerError(),
(request, response) -> {
throw new WellMeetException(ErrorCode.INTERNAL_SERVER_ERROR);
})
.body(RestaurantDetailResponse.class);
}
}
다음 코드는 Kakao Map API 호출해서 반환하는 메소드에 캐싱을 적용한 코드입니다.
@Component
@Slf4j
public class KakaoAPIClient {
private final RestClient kakaoRestClient;
private final String KEYWORD_SEARCH_URL = "/v2/local/search/keyword.json";
public KakaoAPIClient(@Qualifier("kakaoRestClient") RestClient kakaoRestClient) {
this.kakaoRestClient = kakaoRestClient;
}
@Cacheable(value = "location")
public KakaoCoordinateResponse getFirstPlaceCoordinate(String query) {
KakaoKeywordSearchResponse response = kakaoRestClient.get()
.uri(uriBuilder -> uriBuilder
.path(KEYWORD_SEARCH_URL)
.queryParam("query", query)
.queryParam("size", 1) // 첫 번째 결과만
.build())
.retrieve()
.body(KakaoKeywordSearchResponse.class);
KakaoDocumentResponse document = response.getDocuments().get(0);
log.info("place name: {}", document.getPlaceName());
log.info("address name: {}", document.getAddressName());
return new KakaoCoordinateResponse(Double.parseDouble(document.getLongitude()),
Double.parseDouble(document.getLatitude()),
document.getPlaceName());
}
}
@Cacheable 동작 원리
@Cacheable은 내부적으로 @AOP를 활용합니다.
AOP는 빈을 등록할 때 실제 빈 객체를 target 객체로 해서 프록시 객체로 한 번 감싼 다음 프록시 객체를 대신 등록합니다.
그리고 이 프록시 객체가 target 객체에 대한 요청을 받아 작업 수행 전과 후에 원하는 로직을 추가할 수 있습니다.
@Cacheable이 붙은 메소드 같은 경우 요청이 들어왔을 때 가장 먼저 캐시 저장소에서 캐싱된 데이터가 있는지 확인합니다.
있다면 target 객체의 메소드를 실행하지 않고 캐시 데이터를 반환합니다.
없다면 target 객체의 메소드를 실행한 뒤, 그 응답을 캐시 저장소에 캐싱합니다.
로컬 캐시의 문제점 1 - 오래된 데이터
로컬 캐시의 첫 번째 문제점은 오래된 데이터입니다.
바로 데이터가 변경되었는데 로컬 캐시에는 오래된 데이터가 저장되어 실제 변경된 데이터가 반영되지 않은 경우입니다.
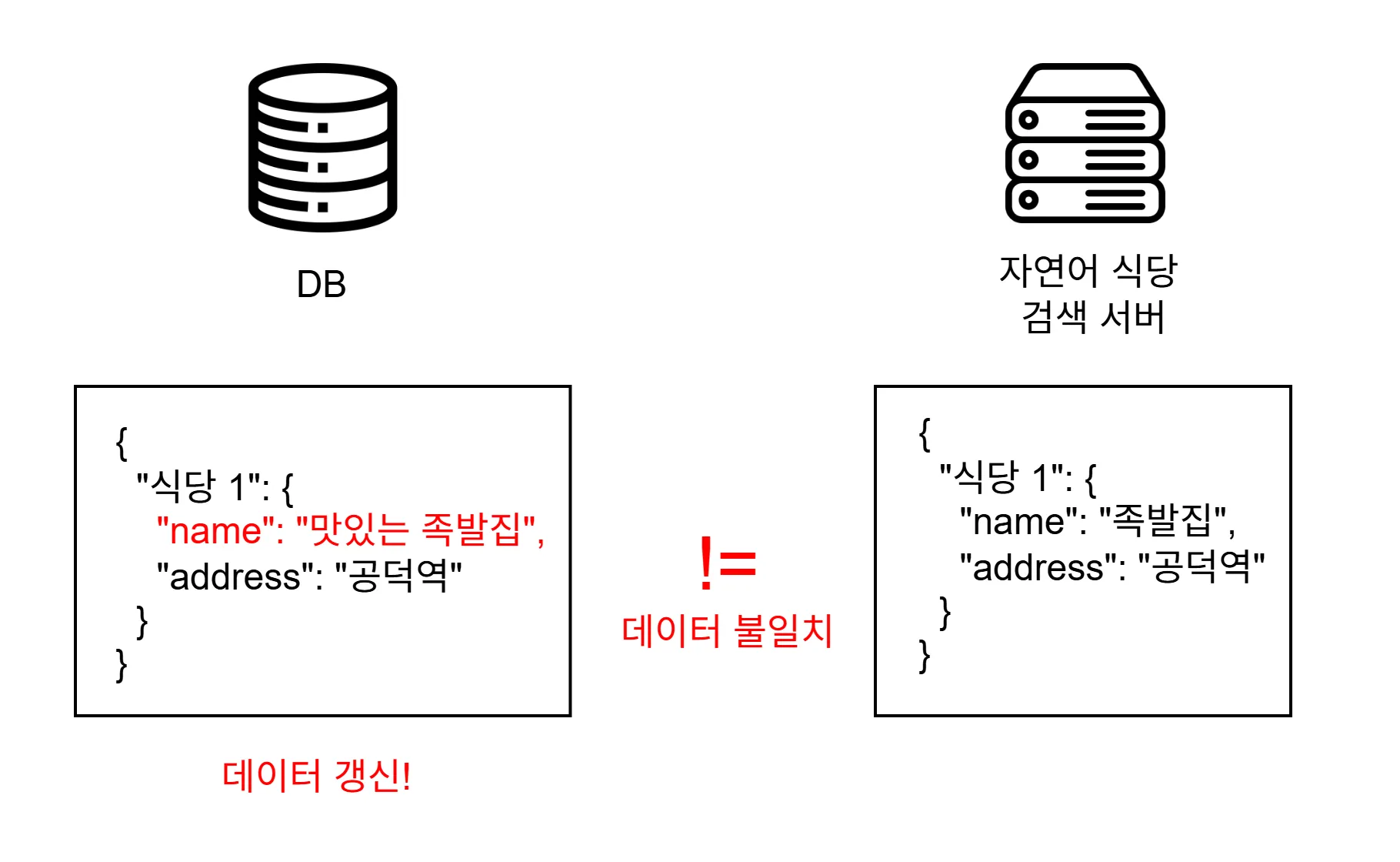
이 경우 두 가지 해결 방법이 있습니다.
- TTL 시간을 줄입니다.
- 데이터가 변경되었을 때, 캐시를 무효화합니다.
1번은 설정이 간단하지만 실제 API 호출 횟수가 늘어난다는 단점이 있습니다.
2번은 데이터가 변경되었을 때, 거의 실시간으로 캐시를 무효화할 수 있지만 추가적인 구현이 필요합니다.
로컬 캐시의 문제점 2 - 분산 환경에서 로컬 캐시 간 불일치
로컬 캐시의 두 번째 문제점은 분산 환경에서 로컬 캐시 간 불일치가 발생할 수 있습니다.

만약 서버를 scale out하게 될 경우 로컬 메모리에 저장된 캐시 데이터가 다를 수 있습니다.
해결 방법 - 데이터 변경이 발생했을 때 캐시 무효화
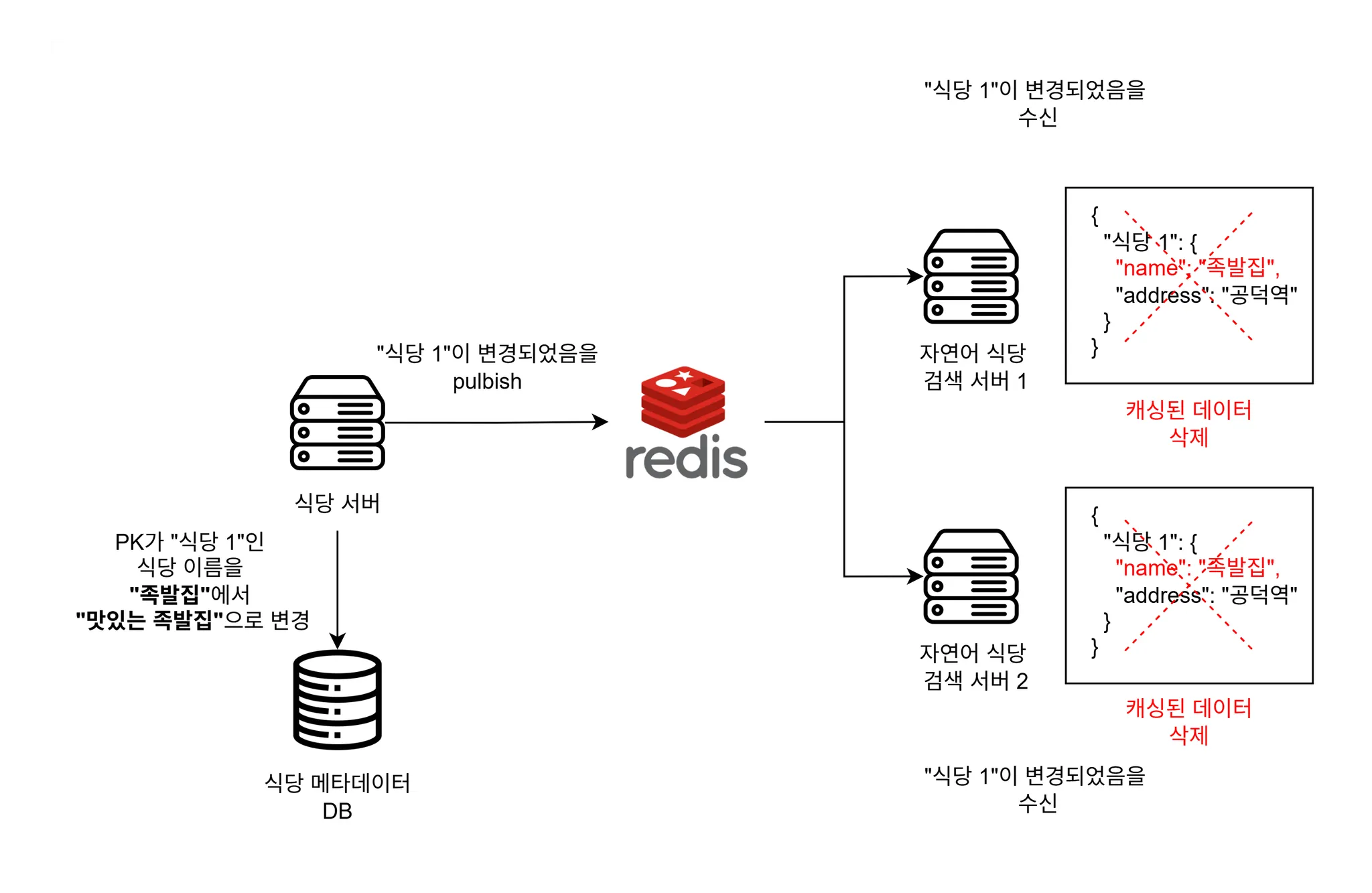
이 두 가지 문제점을 해결할 방법으로 저는 redis pub/sub을 통해 변경 사항을 데이터를 캐싱하는 서버에게 알려주기로 결정했습니다.