개요
On-Premise 환경에서 k8s cluster를 구축해보려고 합니다.
container 기술 개념 정리
k8s에 대해 이해하기 위해 먼저 container 기술에 대한 개념 정리를 하려고 합니다.
container 기술이란?
container 기술이란 가상화 기술의 한 종류로 guest OS를 사용하지 않기 때문에 가상 환경 생성 비용이 비교적 낮은 기술입니다.
가상화 기술에는 hosted OS형, 하이퍼바이저형, 컨테이너형이 있는데 각 기술의 차이점은 다음과 같습니다.

Low-Level container runtime이란?
저수준 container runtime은 Linux 기준으로 namespace와 cgroup와 같은 기능을 통해 container를 실행하는 기능만을 제공합니다.
여기서 namespace란 시스템의 리소스를 분리해서 실행할 수 있게 해주는 기능이고 cgroup은 프로세스 그룹 단위로 시스템 자원의 사용을 제한하고 모니터링 해주는 기능입니다.
주로 고수준 continaer runtime에 의해 호출됩니다.
대표적인 저수준 container runtime으로 runC가 존재합니다.
High-Level container runtime이란?
container runtime이란 컨테이너의 생성, 실행, 관리를 담당하는 핵심 소프트웨어입니다.
컨테이너의 전체 생명 주기, 리소스, 격리 환경, Host OS와의 상호작용을 담당합니다.
대표적인 container runtime으로 contaierd, CRI-O와 같은 것들이 있습니다.
OCI (Open Container Initiative)란?
처음에는 다양한 container 기술들이 나오면서 container 기술에 대한 표준 규격이 존재하지 않았습니다.
그래서 container 기술에 대한 업계 표준을 만들기 위해 OCI를 구성하였습니다.
OCI에서 제시하는 컨테이너가 만족해야할 5가지 원칙은 다음과 같습니다.
| 표준 동작 (Standard Operations) |
• 표준 컨테이너 도구들을 이용해서 컨테이너의 생성, 시작, 정지가 가능해야 함 • 표준 파일 시스템 도구를 통해서 컨테이너의 스냅샷과 복사가 가능해야 함 • 표준 네트워크 도구들을 통해서 컨테이너의 업로드와 다운로드가 가능해야 함 |
| 내용 중립성 (Content-agnostic) |
•표준 컨테이너는 컨테이너가 담고 있는 애플리케이션의 종류에 상관없이 표준 동작들이 동일하게 동작해야 함 |
| 인프라 중립성 (Infrastructure-agnostic) |
•표준 컨테이너는 OCI 지원 인프라라면 종류에 상관없이 컨테이너 실행이 가능해야 함 |
| 자동화를 위한 설계(Designed for Automation) |
•표준 컨테이너는 컨테이너 내용과 인프라 종류에 상관없이 동일한 표준 동작을 지원하기 때문에 자동화가 용이함 |
| 산업 수준의 배포(Industrygrade delivery) |
•표준 컨테이너는 기업 규모에 상관없이 산업 수준의 배포가 가능해야 함 |
OCI의 주요 구성 요소는 다음과 같습니다.
| 구성 | 요소 | 내용 |
| image-spec | 컨테이너 이미지 디스크 포맷 | https://github.com/opencontainers/image-spec |
| image-tools | OCI 이미지 명세에 따라 동작하는 도구 모음 | https://github.com/opencontainers/image-tools |
| runtime-spec | 컨테이너의 설정 방법, 실행 환경, 라이프사이클을 명시 | https://github.com/opencontainers/runtime-spec |
| runtime-tools | OCI 런타임 명세에 따라 동작하는 도구 모음 | https://github.com/opencontainers/runtime-tools |
| runc | OCI 표준에 따라 컨테이너를 생성하고 실행할 수 있는 명령형 도구 | https://github.com/opencontainers/runc |
| go-digest | 컨테이너 생태계에서 광범위하게 활용될 수 있는 공통 다이제스트(digest) 패키지 | https://github.com/opencontainers/go-digest |
| selinux | 컨테이너에 범용적으로 적용될 있는 SELinux 설정 | https://github. |
출처: http://www.opennaru.com/kubernetes/open-container-initiative/
컨테이너 기술에 대한 표준화 – OCI ( OPEN CONTAINER INITIATIVE )
컨테이너 기술에 대한 표준화 단체인 Open Container Initiative는 2015 년 6 월에 레드햇, Docker, CoreOS, Google, IBM Red Hat, Amazon Web Services, VMware,The Linux Foundation 등이
www.opennaru.com
CRI (Container Runtime Inteface)
CRI는 k8s가 container runtime과 통신하기 위한 인터페이스입니다.
containerd와 CRi-O와 같은 고수준 container runtime은 CRI를 구현하여 k8s와 통합될 수 있습니다.

k8s 아키텍처
이제 지금까지 배운 container 개념들을 기반으로 k8s가 어떤 식으로 container를 관리하는지 알아봅시다.
먼저 kubelet은 쿠버네티스 클러스터 각 노드에서 실행되는 핵심 에이전트로 pod와 container를 관리하며 worker node와 control plane node 간 통신을 담당합니다.

- kubelet은 CRI (Container Runtime Interface)를 활용하여 High-level container runtime(containerd, CRI-O)을 호출합니다.
- 고수준 continaer runtime은 OCI(Open Container Initiative)를 활용하여 runC와 같은 Low-level container runtime을 호출하여 container를 생성합니다.
- 최신 k8s는 docker engine 자체를 사용하지 않고 기본적으로 containerd를 container runtime으로 사용합니다.
개념 정리를 마무리 했으니 이제 k8s를 구축해봅시다.
k8s cluster architecture
k8s에서 사양하는 다양한 컴포넌트를 기준으로 cluster architecture에 대해 알아봅시다.

control plane node
control plane node는 worker node 및 clsuter에 파드들을 제어하는 역할을 수행합니다.
실제 애플리케이션 실행은 worker node가 담당하고 cluster의 상태를 관리합니다.
다음과 같은 구성 요소들이 존재합니다.
- kube-apiserver: k8s API를 제공하며 kubectl 명령어 등을 통해 cluster에 대한 요청을 처리합니다.
- etcd: key-value storage로 cluster에 대한 데이터를 보관하고 있습니다.
- kube-scheduler: 노드가 배정되지 않은 파드를 감지하고 실행할 노드를 선택합니다.
- kube-controller-manager: cluster의 상태를 감지하고 정의한 상태를 유지하기 위해 조치를 취하는 controller를 실행합니다.
worker node
worker node는 실제 애플리케이션 실행을 담당합니다. 내부에 파드들이 실행됩니다.
다음과 같은 구성 요소들이 존재합니다.
- kubelet: 각 노드에서 실행되는 agent로 pod의 container의 동작을 관리합니다.
- kube-proxy: 각 노드에서 실행되는 네트워크 프록시로 내부 네트워크나 바깥에서 파드로 네트워크 통신을 할 수 있게 합니다. k8s service의 구현체입니다. 만약 CNI plugin을 사용한다면 굳이 kube-proxy를 사용할 필요가 없습니다.
- Container Runtime: 컨테이너 실행을 담당하는 소프트웨어입니다. k8s는 containerd, CRI-O와 같은 container runtime도 지원하고 이외에도 k8s CRI 구현체도 지원합니다.
Add On
k8s resource인 DaemonSet, Deployment 등을 사용하여 cluster 수준의 기능을 제공합니다. (kube-system namespace에 속함)
다양한 Add On이 존재하지만 대표적인 Add On들은 다음과 같은 것들이 존재합니다.
- DNS: k8s 서비스에 대한 DNS 레코드를 제공하는 DNS 서버입니다. k8s에 의해 실행된 container는 DNS query를 날릴 때 자동으로 이 DNS 서버를 포함합니다.
- logging: container log를 중앙 로그 저장소에 저장합니다.
- network plugin: CNI를 구현하는 소프트웨어 컴포넌트입니다. 파드에 IP 주소를 할당하고 cluster 내에서 통신할 수 있게 하빈다.
control plane node, worker node 공통 세팅
먼저 VM의 내부 세팅이 다음과 같은지 확인합니다.
- 모든 서버의 시간이 ntp를 통해 동기화 되어있는지 확인
- 모든 서버의 MAC 주소가 다른지 확인
- 모든 서버가 2GB 메모리, CPU 2개 이상 가지는지 확인
1. swap 기능 비활성화
sudo swapoff -a
swap은 메모리가 부족할 때 disk를 사용하는 설정입니다.
swap이 활성화 되었다면 k8s가 pod의 메모리를 관리할 때 혼동을 줄 수 있습니다.
2. overlayFS, bridge 커널 모듈 활성화
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
# 필요한 sysctl 파라미터를 설정하면, 재부팅 후에도 값이 유지된다.
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
# 재부팅하지 않고 sysctl 파라미터 적용하기
sudo sysctl --system
overlayFS 모듈을 활성화하는 이유는 docker나 containerd와 같은 container runtime이 이 모듈을 사용하여 image의 layer 구조를 관리하기 때문입니다.
br_netfilter 모듈을 활성화하는 이유는 bridge network traffic이 iptables를 통과하게 하기 위함입니다.
k8s 관점에서 다음 3가지 옵션에 대해 알아봅시다.
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
- net.bridge.bridge-nf-call-iptables
- ipv4 트래픽을 iptables가 처리하도록 설정합니다.
- service의 가상 IP를 실제 Pod IP로 변환하기 위해 사용합니다. (NAT)
- net.bridge.bridge-nf-call-ip6tables
- ipv6 트래픽을 iptables가 처리하도록 설정합니다.
- service의 가상 IP를 실제 Pod IP로 변환하기 위해 사용합니다. (NAT)
- ipv6 트래픽을 iptables가 처리하도록 설정합니다.
- net.ipv4.ip_forward
- 시스템이 네트워크 패킷을 다른 네트워크 인터페이스로 전달할 수 있는 기능입니다.
- 비활성화한다면 시스템이 자신에게 도착한 패킷만 처리합니다.
- 이 옵션을 활성화해야 서로 다른 노드에 있는 파드 간 통신이 가능합니다.
bridge는 switch와 비슷하게 동작을 하며 MAC 주소를 기반으로 traffic을 전달합니다.
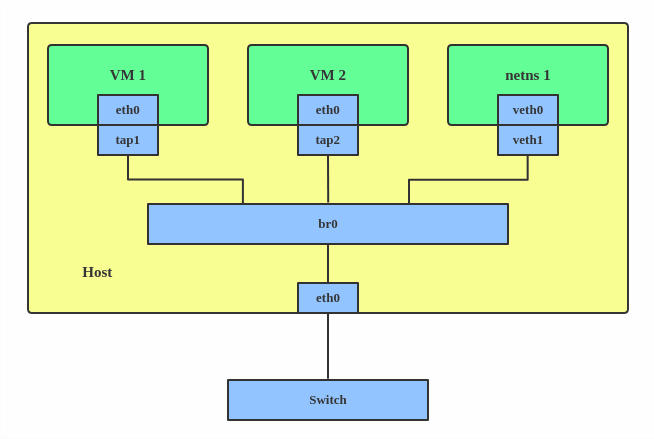
br_netfilter 모듈을 활성화하면 bridge를 지나는 traffic이 iptables를 통과하게 합니다.
일반 bridge는 MAC 주소 기반으로 traffic을 전달하기 때문에 ip 주소를 보지 않지만 br_netfilter 모듈을 통해 bridge에 iptables의 규칙을 적용할 수 있습니다.
파드 간 통신을 위해 Service를 정의하면 kube proxy가 iptables 규칙을 추가하고 이에 따라 적절히 pod에게 traffic을 전달할 수 있습니다.
3. container runtime 설치 (containerd)
k8s는 기본적으로 containerd라는 container runtime을 사용합니다.
containerd를 설치하는 방법은 아래 github를 참고하면 됩니다.
https://github.com/containerd/containerd/blob/main/docs/getting-started.md
containerd/docs/getting-started.md at main · containerd/containerd
An open and reliable container runtime. Contribute to containerd/containerd development by creating an account on GitHub.
github.com
다양한 방식이 나오는데 이 중 apt를 활용해서 containerd.io 패키지를 선택하는 방법을 사용해보겠습니다.
먼저 docker의 apt repository를 설정합니다.
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
ca-certificates는 CA에서 제공해주는 인증서가 포함된 패키지로 https 통신을 위해 필요합니다.
GPG key는 공개 키, 비밀 키가 존재하고 이를 활용하여 변조되지 않았다는 것을 알 수 있기 때문에 필요합니다.
그 후 apt source에 repository를 추가하고 update하면 이제 containerd를 다운받을 수 있습니다.
containerd.io 패키지를 다운받습니다.
containerd.io 패키지는 containerd와 runc를 포함하고 있습니다. (CNI plugin은 미포함)
apt install containerd.io
보통 containerd의 설정 파일은 CRI가 비활성화 되어 있습니다.
개념 정리를 할 때 배웠듯이 CRI를 활성화해야 kubelet이 High-Level container runtime을 호출할 수 있습니다.
/etc/containerd/config.toml 파일은 먼저 default 값으로 변경합니다.
containerd config default | sudo tee /etc/containerd/config.toml
config 파일을 다시 열어보면 plugin에 CRI가 포함된 것을 확인할 수 있습니다.
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
...
재시작해서 설정을 적용합니다.
systemctl restart containerd
4. cgroup driver 설정
개념 설명에서 보았듯이 리눅스에서 cgroup은 프로세스 그룹 단위로 시스템 자원의 사용을 제한하고 모니터링 해주는 기능으로 kubelet과 container runtime는 모두 같은 cgroup driver를 사용해야 합니다.
두 가지 cgroup driver가 사용 가능합니다.
- cgroupfs: kubelet의 기본 cgroup driver로 직접 cgroup 파일 시스템과 상호작용합니다.
- systemd: cgroup과 긴밀하게 통합되어 있으면 systemd 단위로 cgroup을 할당합니다.
systemd가 init 시스템으로 선택되었을 때는 kubelet과 container runtime 모두 systemd를 cgroup driver로 사용하는 편이 좋습니다.
containerd의 설정 파일(/etc/containerd/config.toml)에서 systemd cgroup driver를 선택해봅시다.
이전에 default로 생성했던 config.toml 파일을 열어서 plugin 블록의 systemd_cgroup을 true로 변경합니다.
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
...
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
...
SystemdCgroup = true
...
...
설정을 적용하기 위해 containerd를 재시작합니다.
systemctl restart containerd
kubelet의 cgroup driver를 설정하려면 KubeletConfiguration을 수정하면 됩니다.
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
...
cgroupDriver: systemd
kubelet은 기본적으로 systemd를 cgroup driver로 사용하기 때문에 지금은 직접 변경하지 않아도 됩니다.
5. kubectl, kubeadm, kubelet 설치
버전마다 설치 방법이 다를 수 있으니 공식 문서를 참고하는 것을 추천드립니다.
https://kubernetes.io/ko/docs/tasks/tools/install-kubectl-linux/
리눅스에 kubectl 설치 및 설정
시작하기 전에 클러스터의 마이너(minor) 버전 차이 내에 있는 kubectl 버전을 사용해야 한다. 예를 들어, v1.34 클라이언트는 v1.33, v1.34, v1.35의 컨트롤 플레인과 연동될 수 있다. 호환되는 최신 버전
kubernetes.io
kubeadm 설치하기
이 페이지에서는 kubeadm 툴박스 설치 방법을 보여준다. 이 설치 프로세스를 수행한 후 kubeadm으로 클러스터를 만드는 방법에 대한 자세한 내용은 kubeadm으로 클러스터 생성하기 페이지를 참고한다.
kubernetes.io
sudo apt-get update
# apt-transport-https는 더미 패키지일 수 있다. 그렇다면 해당 패키지를 건너뛸 수 있다
sudo apt-get install -y apt-transport-https ca-certificates curl gpg
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.34/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.34/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl지금까지 공통 세팅이었습니다.
만약 VM에서 여러 node를 띄우려고 한다면 여기서 VM 복제를 하시는 것을 추천드립니다.
이제부터 Control Plande node와 Worker node를 세팅해봅시다.
Control Plane node 세팅
1. k8s cluster 초기화
kubeadm init --apiserver-advertise-address [control plane api server 주소] \
--pod-network-cidr=[pod network 대역] \
--cri-socket unix:///run/containerd/containerd.sock
- --apiserver-advertise-address: 다른 노드가 control plane 노드에게 접근할 수 있는 IP 주소.
- --pod-network-cidr: k8s pod의 네트워크 대역. 각 서버의 네트워크 대역과 중복되지 않게 선택.
- --cri-socket unix:///run/containerd/containerd.sock: k8s가 containerd를 container runtime으로 사용하도록 설정.
--apiserver-advertise-address는 control plane node에게 API 요청을 보내기 위한 주소입니다.
control plane node의 주소를 ifconfig 명령어로 확인해봅시다.
to see the stack trace of this error execute with --v=5 or higher
enp0s3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.35.243 netmask 255.255.255.0 broadcast 192.168.35.255
inet6 fe80::a00:27ff:fe8d:e195 prefixlen 64 scopeid 0x20<link>
ether 08:00:27:8d:e1:95 txqueuelen 1000 (Ethernet)
RX packets 156922 bytes 206397707 (206.3 MB)
RX errors 725 dropped 0 overruns 0 frame 725
TX packets 19159 bytes 1758530 (1.7 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 1469 bytes 158786 (158.7 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1469 bytes 158786 (158.7 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
enp0s3의 inet을 보면 192.168.35.243인 것을 확인할 수 있습니다.
--pod-network-cidr은 pod의 네트워크 대역으로 서버의 대역과 겹치지 않게 설정합니다.
그리고 pod network의 network size는 사용할 노드의 수를 고려하여 설정해야 합니다.
kube-controller-manager의 --node-cidr-mask-size의 기본 값은 24입니다.
노드마다 서브넷이 /24 즉, 2^8 = 256개의 IP 주소를 할당합니다.
만약 10.0.0.0/24와 같은 값을 설정한다면 하나의 노드에만 pod를 배치할 수 있다는 뜻이 됩니다.
저는 여러 노드를 띄울 예정이기 때문에 10.0.0.0/16로 설정하겠습니다.
kubeadm init --apiserver-advertise-address 192.168.35.243 \
--pod-network-cidr=10.0.0.0/16 \
--cri-socket unix:///run/containerd/containerd.sock
이제 필요한 image들을 다운로드 받고 다음 문구가 뜨면 cluster 설정이 완료됩니다.
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.35.243:6443 --token 9x6mkm.y9cfln4wmy273htx \
--discovery-token-ca-cert-hash sha256:4e40aaab0e8ac49db76b8183d647dbcbb3e1ee0bfa570bf1d8b9dd3d3187760f
참고로 kubeadm으로 cluster를 초기화 할 때 사용하는 이미지 리스트는
kubeadm config images list 명령어로 확인할 수 있고 다음과 같은 이미지들을 다운로드 받습니다.
registry.k8s.io/kube-apiserver:v1.34.1
registry.k8s.io/kube-controller-manager:v1.34.1
registry.k8s.io/kube-scheduler:v1.34.1
registry.k8s.io/kube-proxy:v1.34.1
registry.k8s.io/coredns/coredns:v1.12.1
registry.k8s.io/pause:3.10.1
registry.k8s.io/etcd:3.6.4-0
kubeadm config images pull 명령어로 cluster 초기화 전에 미리 다운로드 받을 수도 있습니다.
이제 cluster 완료 출력 문구가 시키는대로 하면 됩니다.
저는 일반 유저이므로 다음 명령어를 입력하겠습니다.
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
2. container network add on 설치
k8s 컨테이너 간 통신을 위해 CNI(Container Network Interface)를 설치해야 합니다.
cilium, multus, calico 등 다양한 CNI가 있지만 그 중 calico를 설치해보겠습니다.
공식 문서의 설치 가이드는 다음과 같습니다.
https://docs.tigera.io/calico/latest/getting-started/kubernetes/self-managed-onprem/onpremises
Installing on on-premises deployments | Calico Documentation
Install Calico networking and network policy for on-premises deployments.
docs.tigera.io
curl https://raw.githubusercontent.com/projectcalico/calico/v3.31.0/manifests/calico.yaml -O
kubectl apply -f calico.yaml
이제 다음 명령어로 calico가 running 상태인지 확인합니다.
kubectl get po -n kube-system
처음에는 pending 상태이고 조금 기다리면 running 상태가 됩니다.
user@master-1:~$ kubectl get po -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-5766bdd7c-qh64z 0/1 ContainerCreating 0 22m
calico-node-7cnjp 1/1 Running 0 22m
coredns-66bc5c9577-95fts 1/1 Running 0 146m
coredns-66bc5c9577-rvwxx 1/1 Running 0 146m
etcd-master-1 1/1 Running 0 146m
kube-apiserver-master-1 1/1 Running 0 146m
kube-controller-manager-master-1 1/1 Running 7 (91m ago) 146m
kube-proxy-5cmt7 1/1 Running 0 146m
kube-scheduler-master-1 1/1 Running 8 (91m ago) 146m
Worker node 세팅
이제 worker node를 세팅해봅시다.
control plane node에서 k8s cluster를 생성했을 때 나온 출력 문구에 worker node가 k8s cluster에 참가하는 명령어가 함께 나왔습니다.
worker node에서 해당 명령어를 복사해서 입력해봅시다.
저는 다음과 같은 명령어를 입력했습니다.
kubeadm join 192.168.35.243:6443 --token 9x6mkm.y9cfln4wmy273htx \
--discovery-token-ca-cert-hash sha256:4e40aaab0e8ac49db76b8183d647dbcbb3e1ee0bfa570bf1d8b9dd3d3187760f
성공적으로 참가했다면 control plane node에서 kubectl get nodes 명령어를 입력했을 때 worker node가 ready인 상태로 나와야 합니다.
user@master-1:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
master-1 Ready control-plane 3h50m v1.34.1
slave-1 Ready <none> 80m v1.34.1
그리고 이제 worker node에서 kubectl 명령어를 사용할 수 있도록 control plane node의 config 파일을 그대로 가져옵니다.
ubuntu 기준 control plane node의 config 파일은 다음 위치에 존재합니다.
/home/유저이름/.kube/config
worker node에는 .kube 디렉토리를 직접 만들어서 config 파일을 복사해서 넣어줍니다.
worker node에서도 kubectl 명령어가 사용 가능하면 성공한 것입니다.
user@slave-1:~/.kube$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
master-1 Ready control-plane 4h3m v1.34.1
slave-1 Ready <none> 93m v1.34.1
이제 간단하게 nginx pod 3개를 띄워봅시다.
다음과 같은 Deployment와 NodePort type Service를 정의했습니다.
<test.yaml>
apiVersion: apps/v1
kind: Deployment
metadata:
name: simple-nginx-deployment
labels:
app: nginx-test
spec:
replicas: 3
selector:
matchLabels:
app: nginx-test
template:
metadata:
labels:
app: nginx-test
spec:
containers:
- name: nginx-container
image: nginx:latest
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: simple-nginx-service
spec:
selector:
app: nginx-test
ports:
- protocol: TCP
port: 80
targetPort: 80
type: NodePort
적용 후 pod를 출력해봅시다.
kubectl apply -f test.yaml
kubectl get po -o wide
pod가 running중입니다.
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
simple-nginx-deployment-668c96b57f-5zh96 1/1 Running 0 6m58s 10.0.0.219 slave-1 <none> <none>
simple-nginx-deployment-668c96b57f-8z24b 1/1 Running 0 6m58s 10.0.0.218 slave-1 <none> <none>
simple-nginx-deployment-668c96b57f-nqp66 1/1 Running 0 6m58s 10.0.0.217 slave-1 <none> <none>
NodePort 타입 Service도 생성했으니 port를 확인해봅시다.
kubectl get svcNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 5h58m
simple-nginx-service NodePort 10.97.97.1 <none> 80:31786/TCP 7m36s
노드 IP:31786으로 접속했을 때 nginx welcome page가 나오면 성공적으로 배포를 한 것입니다.

출처
https://kubernetes.io/ko/docs/setup/production-environment/container-runtimes/
https://itnext.io/container-network-interface-cni-in-kubernetes-an-introduction-6cd453b622bd