개요
이번 포스팅에서는 Grafana Alerting의 Alert rules, Contact points, Notification policies에 대해 알아보고 간단한 모니터링 알림 시스템을 구축해보려고 합니다.
이전 포스팅에서 kube-prometheus-stack을 활용한 metric 수집 및 알림 시스템을 구축했기 때문에 kube-prometheus-stack의 values.yaml 파일을 override해서 알림 모니터링 시스템을 구현해보겠습니다.
p99 rate를 측정하여 1분 이상일 때 알림을 보내주는 모니터링 시스템을 구축해보겠습니다.
Grafana Alerting
Grafana Alerting은 통합 알림 시스템으로 다양한 데이터 소스 기반의 알림을 중앙에서 관리할 수 있게 해주는 시스템입니다.

Grafana Alerting의 핵심 구성 요소로 Alert rules, Contact points, Notification policies가 존재합니다.
- Contact points: 알림 전송 방식 설정
- Alert rules: 알림이 발생하기 전에 충족되어야 하는 조건
- Notification policy: Contact points 라우팅 설정
하나씩 구현을 해보면서 구체적인 사용법에 대해 알아보겠습니다.
Contact points

알림을 전송할 방식으로 다양한 방식을 제공하고 있습니다. 저는 slack API와 호환이 되는 mattermost를 사용 중이라 slack을 선택하겠습니다.

mattermost에서 incoming webhook을 설정하고 URL을 contact point로 등록했습니다.
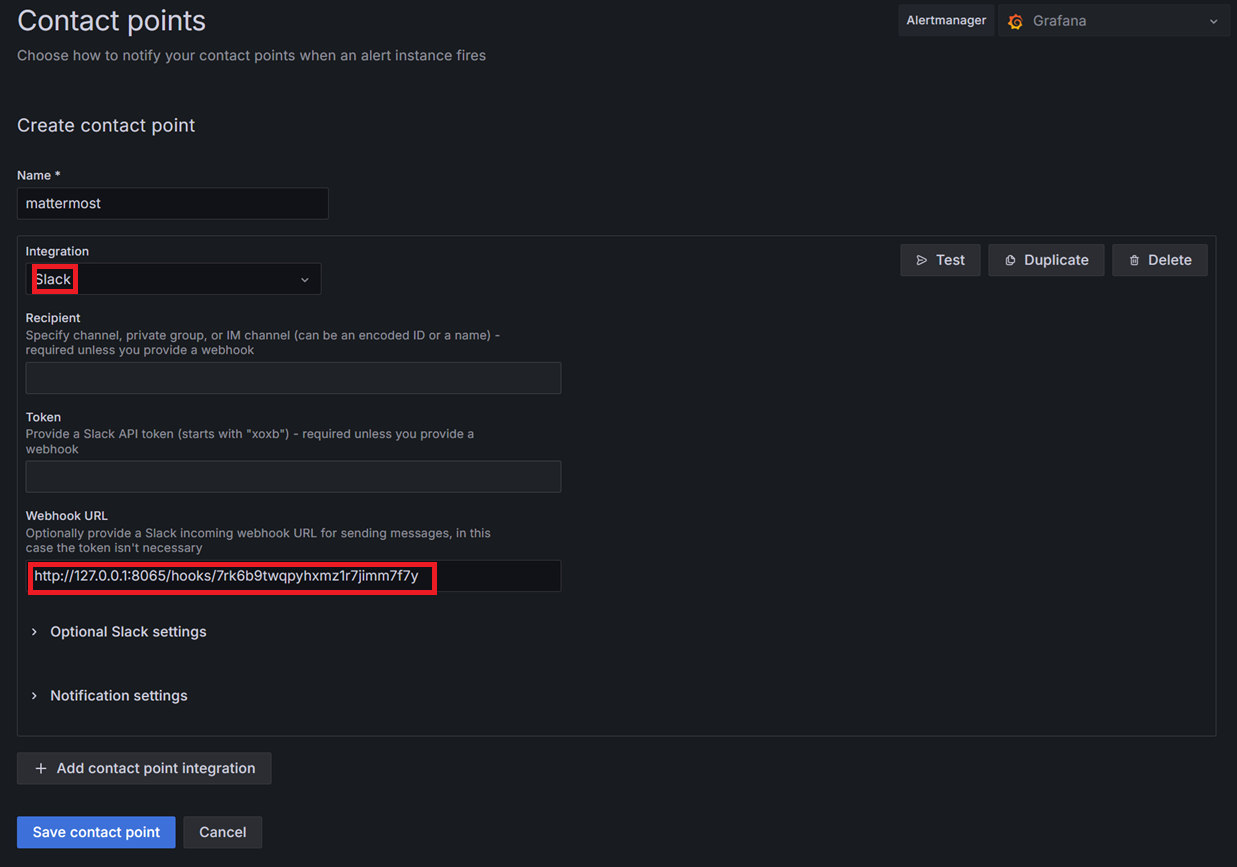
Optional Slack settings에서 title과 body를 설정할 수도 있습니다.
Alert rules
alert rule은 다음과 같은 설정을 해야 합니다.
- alert rule name
- query and alert
- evaluation behavior
- label and notifications
- annotations
alert rule name
alert rule을 식별하기 위한 이름입니다.

query
실행할 쿼리입니다. 저는 API의 p99를 측정하는 쿼리를 작성했습니다.
모든 pod의 요청 횟수를 합산하여 histogram을 만들고 service를 기준으로 p99 latency를 구하는 쿼리입니다.

expressions
다음은 쿼리의 결과를 가공하는 reduce와 임계 값을 설정할 수 있는 Threshold입니다.

지금 reduce를 보면 reduce operation이 필요하지 않다는 warning이 출력되고 있습니다.
reduce는 시계열 데이터를 단일 값으로 압축하는 역할로 제가 지금 작성한 쿼리의 결과는 이미 단일 값이기 때문에 필요하지 않다는 메시지입니다.
reduce는 사용하지 않고 p99 query의 결과를 사용해서 조건을 설정해보겠습니다.

input을 reduce의 결과 값(B)가 아닌 query의 결과 값(A)을 직접 사용했고 query의 결과 값이 60보다 클 때 알림을 전송하도록 설정했습니다.
1분 이상이 걸린 long-request API에 대해서만 조건을 충족(Firing)하고 있습니다.
evluation behavior
evaluation behavior는 위에서 정의한 알림을 발송하기 위해 알림 조건을 만족하는 지속 시간을 설정할 수 있습니다.
- evaluation interval: query 실행 주기
- pending period: 조건 만족 후 경고 상태로 전환되기 전까지 대기하는 시간

evaluation group을 생성하면 evaluation interval을 설정할 수 있습니다.

저는 evaluation interval을 1분으로 설정했고 pending period를 3분으로 설정했습니다.
제가 작성한 쿼리를 1분 단위로 실행하고 3분 동안 조건을 계속 만족했을 때 알림을 전송합니다.
labels and notifications
label과 notification 설정입니다.
label은 alert rule을 구분하기 위한 설정 값이고 notification은 contact point를 선택하여 알림을 전송할 방법을 선택할 수 있습니다.
notification 설정은 두 가지 방법이 있습니다.
- Select contact point: 직접 contact point를 정의
- Use notification policy: network policy를 통해 라우팅
다음과 같이 직접 contact point를 설정할 수 있습니다.

저는 network policy를 사용해보겠습니다. network policy 설정은 Alert rule을 먼저 생성하고 진행하겠습니다.

annotations
마지막으로 annotation을 생성하고 alert rule을 생성합니다.

Notification plicies
Notification polices에서는 알림을 routing하여 원하는 contact point에 전달할 수 있습니다.

Alert rule을 생성할 때 label을 작성해두었는데 이 label을 기반으로 알림을 라우팅 해보겠습니다.
Default policy에 New child policy를 생성합니다. child policy는 기본적으로 parent policy 설정이 적용됩니다.


- Matching labels: notification policy를 적용할 alert rule의 label
- contact point: 알림 전송 수단
- group by: group을 나누는 기준
group에 대해서는 조금 더 자세하게 알아봅시다.
Grouping (그룹화)
개념
- 동일한 특성을 가진 알림들을 하나의 그룹으로 묶는 메커니즘
- 기본 그룹: grafana_folder + alertname
- 커스텀 그룹: namespace, service 등 추가 가능
필요한 이유
- 알림 폭탄(Alert Storm) 방지
- 알림 관리의 효율성
예시
namespace와 service를 기준으로 그룹을 설정했다고 합시다.
이 안의 /users, /orders, /products API에 대해 p99 latency가 1분이 넘어가게 되면 각각 따로 알림을 보내는 것이 아니라 하나의 알람으로 묶어서 보내게 됩니다.
그룹 설정: namespace + service
[Group 1] namespace=projectA, service=api-server
- API /users 응답시간 초과
- API /orders 응답시간 초과
- API /products 응답시간 초과
→ 3개 알림이 하나로 묶여서 전송
하나로 묶어서 보내기 위해서는 조건을 만족할 때마다 특정 시간 동안 알림을 모아두었다가 한 번에 발송합니다.
이 시간이 바로 Group Wait입니다.
2. Group Wait
개념
- 그룹의 첫 알림을 보내기 전 대기 시간
- 이 시간 동안 발생한 알림들을 모아서 한 번에 전송
필요한 이유
- 짧은 시간에 여러 알림 발생 시 한 번에 묶어서 전송
- 초기 알림 폭탄 방지
default 값
- 30s
예시
Group Wait = 30s
00:00:00 - API /users 조건 만족 (firing)
00:00:15 - API /orders 조건 만족 (firing)
00:00:30 - 2개 알림 묶어서 1번 전송
/users와 /orders에 대해 알림 조건을 만족하여 2개의 알림을 하나로 보낸 상황입니다.
이 상태에서 30초가 지났는데 두 API가 여전히 알림 조건을 만족하면 어떻게 될까요?
Group Wait = 30s
00:00:00 - API /users 조건 만족 (firing)
00:00:15 - API /orders 조건 만족 (firing)
00:00:30 - 2개 알림 묶어서 1번 전송
/users와 /orders API가 계속 조건을 만족 중 (firing)
00:01:00 - 이 상황에 대한 알림은 이미 보냈기 때문에 중복 알림 전송 X
해결되지 않았기 때문에 중복 알림을 전송하지 않습니다.
하지만 여기서 /products API 또한 알림 조건을 만족한다면 group에 변화가 생겼기 때문에 알림을 보내야 합니다.
그렇다면 이것도 역시 group wait 시간에 맞춰 30초가 지났을 때 알림을 전송하게 되는 걸까요?
Group Wait = 30s
00:00:00 - API /users 조건 만족 (firing)
00:00:15 - API /orders 조건 만족 (firing)
00:00:30 - 2개 알림 묶어서 1번 전송
/users와 /orders API가 계속 조건을 만족 중 (firing)
00:01:00 - 이 상황에 대한 알림은 이미 보냈기 때문에 중복 알림 전송 X
00:01:05 - API /products 조건 만족 (firing)
00:01:30 - 3개 알림 묶어서 전송?
이 때는 group wait 시간을 따르지 않고 group interval 시간을 따르게 됩니다.
3. Group Interval
개념
- 그룹 내 변화가 있을 때 업데이트 알림을 보내는 주기
- 새로운 알림 추가 또는 기존 알림 해결 시 적용
- 그룹의 전체 상태 스냅샷을 전송 (현재 Firing/Resolved 상태 모두 포함)
필요한 이유
- 이미 알림을 받은 그룹에 대한 업데이트는 급하지 않음
- 너무 잦은 업데이트 방지
- 변화가 있을 때만 알림 (중요!)
default 값
- 5m
예시
Group Wait = 30s
Group Interval = 5m
00:00:00 - API /users 조건 만족 (Firing) (Group Wait 타이머 시작)
00:00:15 - API /orders 조건 만족 (Firing)
00:00:30 - [첫 알림] /users, /orders 묶어서 전송 (Group Wait 적용) (Group Interval 타이머 시작)
/users와 /orders API가 계속 조건을 만족 중 (Firing 상태 유지)
00:03:00 - API /products 조건 만족 (Firing) ← 알림을 보내야 함
00:03:30 - Group Wait 30초 대기? NO! 이미 그룹의 첫 알림을 보냈으므로 Group Interval 적용
00:05:30 - [업데이트 알림] /users, /orders, /products 묶어서 전송
(Group Interval 타이머 재시작)
이후 /users, /orders, /products 모두 계속 조건을 만족하며 변화 없음 (Firing 상태 유지)
00:10:30 - 변화가 없어서 알림 전송 X
(Group Interval 타이머 재시작)
group에서 처음으로 firing이 발생하면 group wait동안 기다렸다가 알림을 한 번에 전송합니다.
group wait이 지나 알림을 전송했다면 group interval 타이머가 실행됩니다.
새로운 알림이 추가되면 Group Interval만큼 대기 후 그룹 전체 상태를 전송합니다.
group wait과 group interval은 너무 많은 알림이 전송되는 것을 방지하기 위한 설정입니다.
또한, 이미 알림을 보내서 관리자가 이상 현상을 감지한 상황에서 계속 알림을 보내지 않기 위한 설정입니다.
그런데 계속 관리자가 문제를 해결하지 않고 방치하면 어떻게 될까요?
변화가 없기 때문에 계속 알림을 보내지 않을 수는 없습니다.
이럴 때 필요한 설정이 Repeat Interval입니다.
4. Repeat Interval
개념
- 그룹 내 변화가 없을 때 반복 알림을 보내는 주기
- 해결되지 않은 알림에 대한 리마인드
- Group Interval과의 차이: 변화 없이 방치될 때 적용
필요한 이유
- 해결되지 않은 문제를 주기적으로 리마인드
- 너무 잦은 반복 알림으로 인한 피로도 방지
default 값
- 4h
예시
Repeat Interval = 4h
00:00:30 - [첫 알림] /users, /orders (Firing) (Repeat Interval 타이머)
00:30:00 - 변화 없음 (알림 X)
01:00:00 - 변화 없음 (알림 X)
02:00:00 - 변화 없음 (알림 X)
04:00:30 - [반복 알림] "아직도 안 고쳤어?" 리마인드
08:00:30 - [반복 알림] "아직도 안 고쳤어?" 또 리마인드
추가적인 예시
위 예시에서 보았던 "변화"는 조건을 만족했다가 (firing 상태 진입) 조건을 만족하지 않았을 때 (resolved 상태 진입)도 포함이 됩니다.
Group Wait = 30s
Group Interval = 5m
00:00:00 - API /users 조건 만족 (Firing)
00:00:15 - API /orders 조건 만족 (Firing)
00:00:30 - [첫 알림] /users, /orders 묶어서 전송 (Group Wait 적용)
← Group Interval 타이머 시작!
/users와 /orders API가 계속 조건을 만족 중 (Firing 상태 유지)
00:03:00 - API /products 조건 만족 (Firing) ← 변화 발생!
00:04:00 - API /orders 해결됨 (Resolved) ← 변화 발생!
00:05:30 - [정기 체크] 변화 있음!
→ /users (Firing), /orders (Resolved), /products (Firing) 전송
← Group Interval 타이머 리셋!
00:08:00 - API /users 해결됨 (Resolved) ← 변화 발생!
00:10:30 - [정기 체크] 변화 있음!
→ /users (Resolved), /products (Firing) 전송
← Group Interval 타이머 리셋!
00:15:30 - [정기 체크] 변화 없음 → 알림 전송 안 함
00:20:30 - [정기 체크] 변화 없음 → 알림 전송 안 함
→ Group Interval마다 주기적으로 그룹 상태를 확인하고,
변화가 있을 때만 현재 그룹의 전체 상태(Firing/Resolved)를 전송합니다.
Grouping 개념 최종 정리
- Grouping (그룹화)
- 동일한 특성(namespace, service 등)을 가진 알림들을 하나로 묶어 알림 폭탄을 방지하고 관련 알림을 한눈에 파악하기 위한 메커니즘
- Group Wait
- 그룹의 첫 알림을 보내기 전 대기 시간으로, 짧은 시간 내 발생한 여러 알림을 모아서 한 번에 전송
- Group Interval
- 첫 알림 이후 주기적으로 그룹 상태를 확인하여 변화가 있을 때만 업데이트 알림을 전송하는 주기
- Repeat Interval
- 그룹 상태에 변화 없이 해결되지 않은 채 방치될 때 주기적으로 리마인드 알림을 보내는 주기
마무리
이렇게 Alert rule, Contact point, Notification policy에 대해 알아보았고 Alert rule을 생성해보았습니다.
일부러 1분 이상 걸리는 API를 호출해보았고 1분 단위로 쿼리를 호출하며 3분 이상 p99 latency의 값이 1분 이상으로 지속될 때 다음과 같이 알림이 오는 것을 확인해보았습니다.

Grafana의 Alert Rule을 활용하면 알림 폭탄을 줄이고 그룹 별로 알림을 효과적으로 관리할 수 있습니다.
프로젝트와 모니터링의 규모가 커질 때 큰 도움이 될 것 같습니다.