JPA 기초 사용법을 공부해보려 한다.
기초적인 사용법만 알아볼 예정으로 데이터베이스는 h2를 쓰려고 한다.
위 사이트에서 다음과 같이 dependencies를 추가해준다.
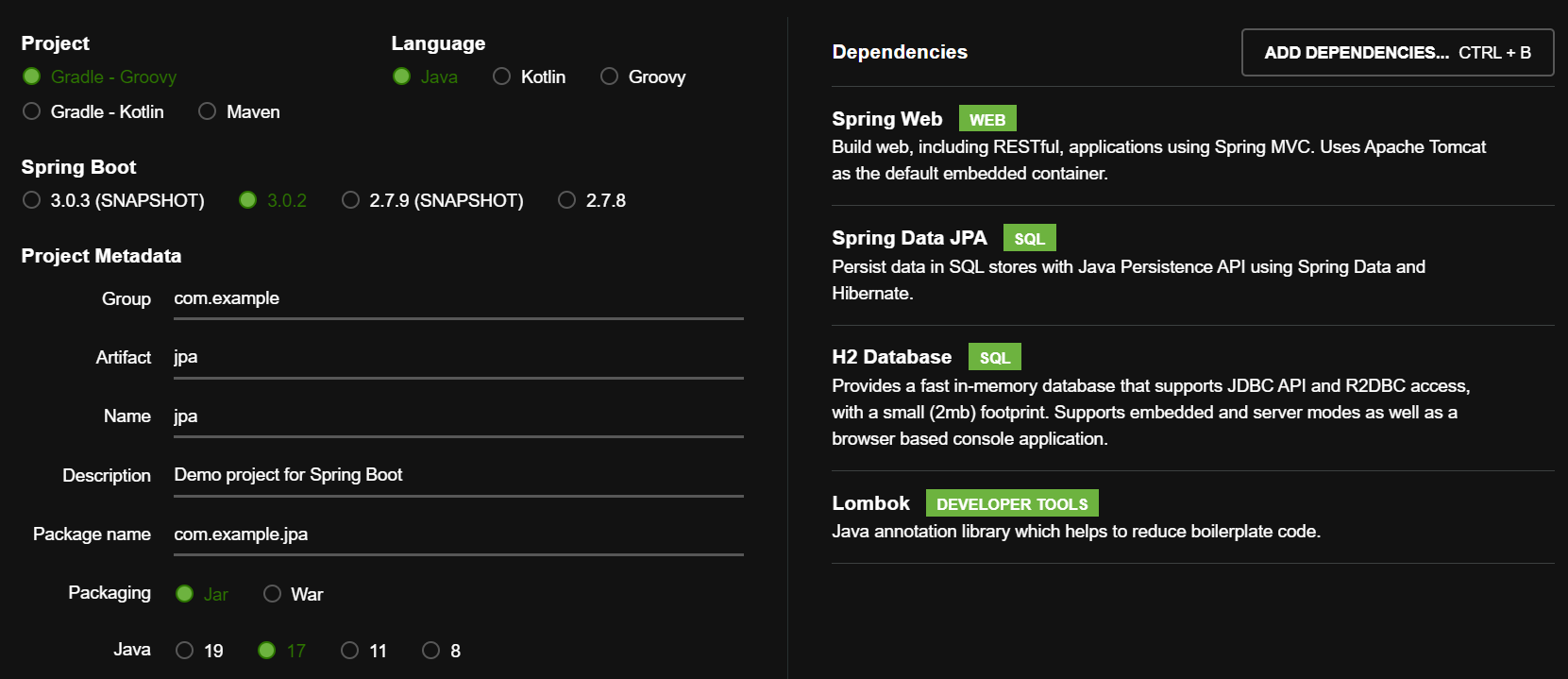
그리고 h2 데이터베이스 사용하도록 설정해야한다.
기본적으로 application.properties 파일이 존재할텐데 이를 사용해도 되지만
가독성이 좋은 application.yml 파일을 사용할 예정이다.
application.properties 우클릭 -> refactor -> rename에서 확장자를 yml으로 바꾸어준다.
그리고 다음 코드를 입력해준다.
<application.yml>
spring:
datasource:
driver-class-name: org.h2.Driver
url: jdbc:h2:mem:test
username: sa
password:
jpa:
database-platform: org.hibernate.dialect.H2Dialect
이제 h2 데이터베이스를 사용할 준비가 되었다.
Entity
이제 의미하는 Item 엔티티를 만들 예정이다.
엔티티는 테이블에 대응하는 클래스이다. 테이블을 만드는 쿼리를 짤 필요 없이 엔티티를 정의하면 만들어준다.
엔티티는 @Entity 어노테이션을 활용하여 만들 수 있다.
기본적으로 사용하는 어노테이션은 다음과 같다.
@Entity : 해당 클래스가 테이블에 대응되도록 엔티티로 선언한다.
@Table : name 속성을 사용하여 대응될 테이블의 이름을 정한다. ex) Table(name = "item_table") 사용하지 않으면 클래스 이름이 곧 테이블 이름이 된다.
@Id : 기본키에 적용하는 어노테이션. 테이블은 반드시 기본키를 가지고 있어야한다.
@GeneratedValue : strategy 속성을 사용하여 기본 키의 생성 전략을 정의한다.
ex) @GeneratedValue(strategy = GenerationType.IDENTITY)
@Enumerated : enum 타입임을 알려줌
@Column : 여러 속성을 사용하여 컬럼의 조건을 정할 수 있다.
이를 사용하여 Item 엔티티를 간단하게 만들어보면 다음과 같다.
@Entity //엔티티 정의
@Table(name="item_table") //사용하지 않으면 클래스 이름이 테이블 이름이 됨
@Getter //lombok getter
@Setter //lombok setter
public class Item {
@Id //기본키를 의미. 반드시 기본키를 가져야함.
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@NonNull
@Column(unique = true, length=10) //유일하고 최대 길이가 10.
private String itemName;
@NonNull
@Column(name="item_price") //컬럼 이름을 item_price로 지정. 사용하지 않으면 필드 이름이 곧 컬럼 이름이 됨.
private int price;
}
Repository
이제 이 엔티티를 생성하고 저장하려면 Repository를 정의해야한다.
public interface ItemRepository extends JpaRepository<Item, Long> {
}Jpa의 장점은 실제로 구현체를 만들지 않고 interface만으로도 레포지토리 기능을 수행할 수 있다는 점이다.
위처럼 인터페이스만 만들어도 사용할 수 있다.
기본적인 메소드들을 알아보면
1. save(entity) : 레포지토리에 엔티티를 저장한다.
2. delete(entity) : 레포지토리에서 엔티티를 삭제한다.
3. findById(id) : 레포지토리에서 기본키를 기준으로 검색해서 엔티티를 반환한다.
4. findAll() : 레포지토리에서 모든 엔티티를 리스트로 반환한다.
4. count() : 레포지토리에 존재하는 엔티티의 개수를 반환한다.
5. existsById(id) : 레포지토리에서 해당 기본키가 존재하면 true 아니면 false를 반환한다.
다른 필드 값을 기준으로 검색
JpaRepository에서는 기본적으로 검색 메소드들을 제공하는데 다른 필드 값을 기준으로 검색을 하고 싶을 수도 있다.
이럴 때는 JpaRepository 인터페이스에서 메소드를 정의하면 된다.
구체적인 내용을 정의할 필요는 없고 반환 타입, 메소드 이름, 파라미터만 정의하면 된다.
메소드 이름에 규칙이 존재하는데 이러한 규칙을 지키기만 하면 직접 내용을 구현할 필요가 없다.
규칙은 다음과 같다.
find + 엔티티 이름 + By + 필드 이름
예를 들어 위에서 정의한 Item 엔티티의 itemName을 기준으로 검색을 하고 싶다면 인터페이스에 다음과 같이 정의하면 된다.
public interface ItemRepository extends JpaRepository<Item, Long> {
Item findByItemNm(String itemNm);
}itemName을 unique한 값으로 정의했기 때문에 반환 타입은 Item이다.
만약 중복을 허용했다면 반환 타입을 List<Item>로 만들면 된다.
두 가지 필드를 기준으로 검색을 할 수도 있다.
find + 엔티티 이름 + By + 필드 이름 + And + 필드 이름
find + 엔티티 이름 + By + 필드 이름 + Or + 필드 이름
숫자의 경우 범위를 정할수도 있다.
find + 엔티티 이름 + By + 필드 이름 + LessThan
find + 엔티티 이름 + By + 필드 이름 + LessThanEqual
find + 엔티티 이름 + By + 필드 이름 + GreaterThan
find + 엔티티 이름 + By + 필드 이름 + GreaterThanEqual
정렬을 하여 반환할 수도 있다.
find + 엔티티 이름 + By + 필드 이름 + OrderBy + 필드 이름2 + Asc
find + 엔티티 이름 + By + 필드 이름 + OrderBy + 필드 이름2 + Desc
위에서 볼 수 있듯이 Jpa를 사용하면 메소드 이름만 보고도 어떠한 역할을 수행하는지 유추할 수 있다.
'공부 > Spring' 카테고리의 다른 글
| [Spring][Thymeleaf] 공통 레이아웃 적용 (Thymeleaf Layout Dialect) (1) | 2023.02.14 |
|---|---|
| [Spring][Thymeleaf] 타임리프 기초 문법 (2) | 2023.02.12 |
| [Spring][스프링 MVC 1편] 서블릿 기초 사용법 (0) | 2023.02.08 |
| [Spring] JSON과 같이 이미지 요청 받아서 저장 (0) | 2023.02.06 |
| [Spring][Lombok] @Data 어노테이션의 분석 (equals, hashCode) (0) | 2023.02.04 |