웹 캠을 켜고 앞에 손 글씨 숫자를 갖다대면 인식한 숫자를 띄워주는 프로젝트를 진행해보려고 한다.
우선 이번 포스팅에서는 CNN 모델의 특성과 학습을 진행해보자.
CNN (Convolution Neural Network)의 특성
CNN은 합성곱 신경망을 의미한다. 한 번 CNN의 특성을 알아보자.
1. 공간적인 구조 정보 보존
CNN의 경우 공간적인 구조 정보를 보존하면서 학습할 수 있기 때문에 이미지를 처리할 때 좋은 성능을 보여준다.
그렇다면 CNN은 어떻게 공간적인 구조 정보를 보존할 수 있을까?
바로 합성곱 연산(Convolution Operation)을 하기 때문이다.
n x m 크기의 행렬인 커널(kernel)로 이미지를 지나가면서 연산을 진행한다.
참고로 합성곱의 결과 행렬을 특성 맵이라고 한다.
다음 그림은 3 x 3 크기의 커널을 사용하여 합성곱 연산을 하는 과정의 일부이다.
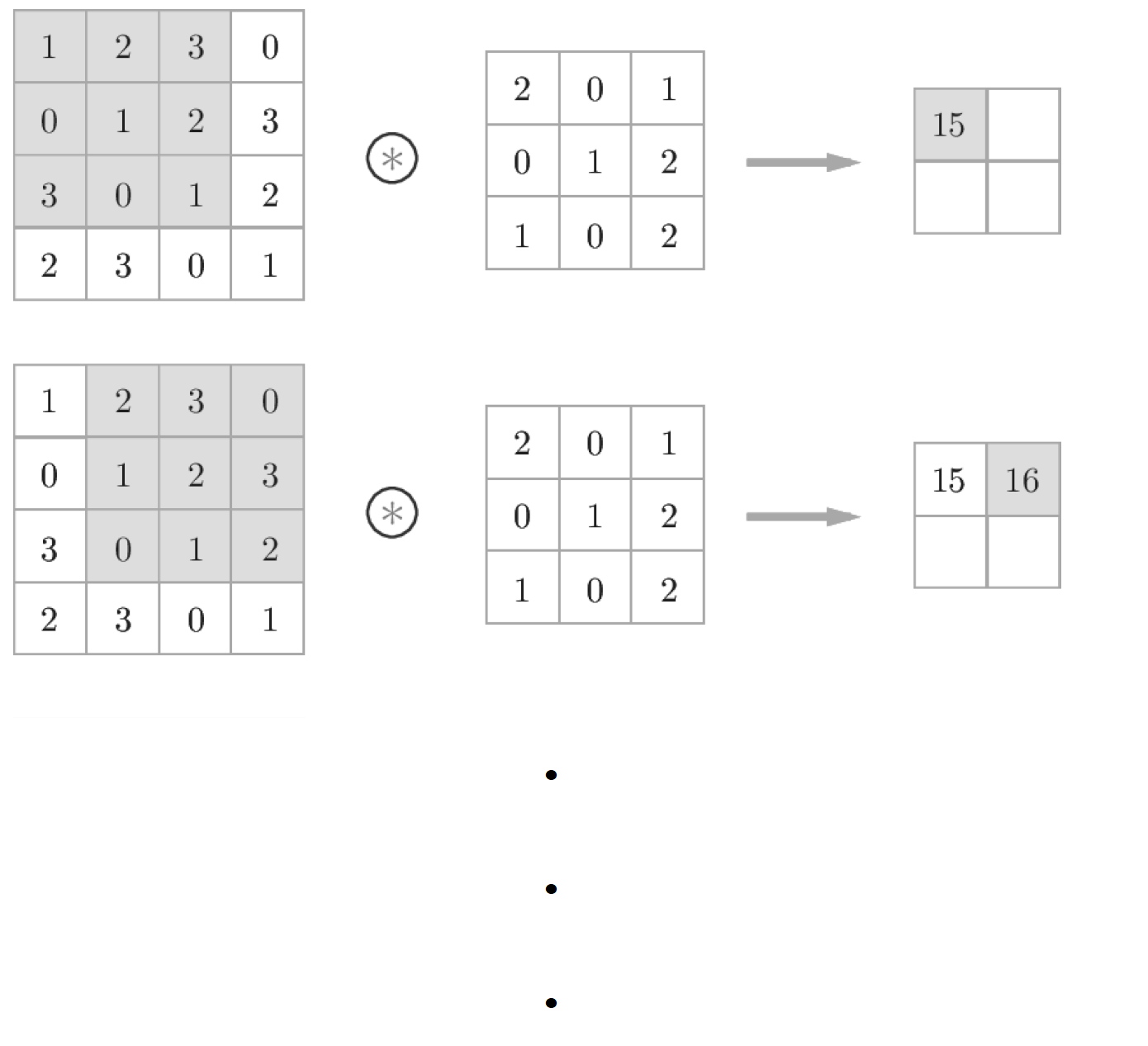
그런데 위에서 보다싶이 합성곱 연산 후 크기가 매우 작아진 모습을 확인할 수 있다.
만약 크기를 유지하고 싶다면 이미지에 패딩을 추가하면 된다.
다음은 제로 패딩을 추가한 이미지이다. 이 이미지로부터 합성곱 연산을 해서 크기를 유지할 수 있다.

패딩, 커널이 한 번에 움직이는 거리 등등을 조절해서 크기를 유지할 수 있다.
참고로 채널 개수가 1인 이미지가 아닌 3인 RGB 이미지라면 커널도 3개가 필요하다.
2. 적은 가중치
CNN은 다층 퍼셉트론과 비교하면 비교적 적은 가중치를 가지고 있다.
위에서 봤듯이 4x4 이미지를 입력받아서 커널을 통해 합성곱 연산을 수행하는데 모든 부분에서 같은 커널을 사용중이다.
즉 가중치는 커널의 크기만큼 존재하는 것이다. 위에서는 3x3 커널을 사용하였는데 단 9개의 가중치만 사용중인 것이다.
다층 퍼셉트론의 경우 공간적인 구조 정보가 유실되고 4x4 이미지를 전부 펼쳐서 사용한다.
즉 4x4x4 = 64개의 가중치를 사용하는 것이다.
CNN은 같은 크기의 결과를 만드는데 9개만 사용하는 것을 생각하면 다층 퍼셉트론보다 적은 가중치를 사용한다.
CNN 구조
이제 CNN의 구조를 알아보자.
CNN은 입력층 (Input Layer), 합성곱층 (Convolution Layer), 풀링층 (Pooling layer), 전결합층 (Fully-Connected Layer), 출력층(Output Layer)로 이루어져 있다.

합성곱층 (Convolution Layer)
합성곱층은 위에서 보았던 합성곱이 이루어지는 계층이다.
합성곱을 하고 난 후 결과에 추가로 ReLU 활성화 함수를 사용한다.
즉 합성곱과 활성화 함수를 사용하는 층이 합성곱층이다.
풀링층(Pooling Layer)
합성곱층을 지난 후 지나는 층이 풀링층이다.
풀링층에서는 특성 맵의 크기를 줄이는 과정이 진행된다.
특성 맵의 크기를 줄이면 가중치의 개수를 줄일 수 있고 연산량 또한 줄일 수 있다.
대표적인 Max Pooling에 대해서 알아보자.

위에서 보는 것과 같이 2x2 max pooling의 경우 2x2로 나누어 그 중 가장 큰 값을 선택한다.
첫 번째 영역에서 가장 큰 값인 20, 두 번째 영역에서 가장 큰 값인 30... 이런식으로 반복되는 모습을 확인할 수 있다.
합성곱층과 달리 풀리층에서는 가중치 학습이 이루어지지 않고 연산 후 채널의 수가 변하지 않는다.
전결합층(Fully-Connected Layer)
전결합층에서는 해당 층의 모든 뉴런과 이전 층의 모든 뉴런이 연결되어있다.
CNN의 전결합층에서는 특징들을 평평하게 펼쳐놓고 분류를 위한 연산을 진행한다.

CNN 구현
이제 파이썬으로 CNN을 구현해보자.
우선 사용할 라이브러리들을 import 한다.
import torch
import torch.nn as nn
import torchvision.datasets as dsets
import torchvision.transforms as transforms
이제 사용할 CNN 모델 클래스를 생성한다.
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 첫 번째 층
self.layer1 = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# 두 번째 층
self.layer2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# 전결합 층
self.fc = nn.Linear(7 * 7 * 64, 10, bias=True)
# 전결합 층 가중치 초기화
nn.init.xavier_uniform(self.fc.weight)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
# 평평하게 펼침
out = out.view(out.size(0), -1)
out = self.fc(out)
return out보면 nn.Module을 상속받고 있는 모습을 볼 수 있다.
__init__()에서 모델의 구조를 정의한다.
합성곱, 활성화 함수, 맥스 풀링, 전결합층을 확인할 수 있다.
실제 연산은 forward 메소드를 통해 이루어진다.
이 forward 메소드는 실제로 우리가 직접 실행하는 것이 아니라 모델 인스턴스의 인자로 넣어주면 자동으로 동작한다.
이 부분은 아래 부분에 적어두겠다.
그러면 합성곱층과 풀링층을 자세히 보자.
첫 번째 층을 다시 보자.
# 첫 번째 층
self.layer1 = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)nn.Conv2d의 경우 첫 번째 인자가 input channel 개수이고 두 번째 인자가 output channel 인자이다.
즉 첫 번째 층에서는 channel의 개수가 1인 텐서를 받아서 channel의 개수가 32인 텐서를 반환한다는 뜻이다.
그리고 padding을 추가하고 있는데 이 padding 값으로 인해 크기를 유지할 수 있다.
이후 활성화 함수를 지나고 맥스 풀링을 진행하는 모습도 확인할 수 있다.
맥스 풀링을 지나고 나면 특성 맵의 크기가 줄어든다.
이번에 사용할 데이터 텐서의 shape는 다음과 같다.
torch.Size([batch size, channel, height, width])batch size는 이후에 data loader를 정의할 때 정의하는 값이다. (아직 정의하지 않았다.)
MNIST 손글씨 데이터는 28*28 크기의 channel이 1인 값이 저장되어있다.
만약 data loader에서 batch size를 100으로 저장해두었다면 처음 데이터를 불러왔을 때 텐서의 shape은 (100, 1, 28, 28)이 된다.
이제 천천히 이 텐서 shape의 변화를 살펴보자.
첫 번째 층
이 텐서가 첫 번째 층의 합성곱 연산을 진행하고 나면 정의한대로 채널의 수가 1에서 32로 늘어난다. (100, 32, 28, 28)
그리고 첫 번째 층의 맥스 풀링 연산을 진행하고 나면 정의한 대로 특성 맵의 크기가 줄어든다. (100, 32, 14, 14)
이제 두 번째 층으로 이동하자.
두 번째 층
이 텐서가 두 번째 층의 합성곱 연산을 진행하고 나면 정의한대로 채널의 수가 32에서 64로 늘어난다. (100, 64, 14, 14)
그리고 두 번째 층의 맥스 풀링 연산을 진행하고 나면 정의한 대로 특성 맵의 크기가 줄어든다. (100, 64, 7, 7)
이제 전결합층으로 이동하자.
전결합층
전결합층으로 이동하기 전에 연산을 위해 텐서의 shape를 변경해야 한다.
손글씨 숫자는 클래스가 10개이므로 최종적으로 10개를 반환하기 위해 self.fc가 nn.Linear(7*7*64, 10)으로 되어있다.
그렇다면 당연히 전결합층으로 들어가기 전 텐서의 shape은 (batch size, 7*7*64)가 되어야 한다.
위에서 batch size가 100이라고 가정했으므로 텐서의 shape은 (100, 7*7*64)로 변형시켜야 한다.
텐서를 펼칠 때는 view를 사용하면 된다.
forward 메소드를 보면 다음과 같이 view를 사용하고 있다.
out = out.view(out.size(0), -1)텐서의 형태는 가장 첫 번째가 batch size라서 batch size를 가져오고 남은 것은 펼치고 있다.
이제 학습에 필요한 데이터 및 변수들을 정의한다.
lr = 0.001
training_epochs = 15
batch_size = 100
mnist_train = dsets.MNIST(
root = './',
train = True,
transform = transforms.ToTensor(),
download = True
)
mnist_test = dsets.MNIST(
root = './',
train = False,
transform = transforms.ToTensor(),
download = True
)
loader = torch.utils.data.DataLoader(dataset=mnist_train, batch_size=batch_size, shuffle=True, drop_last=True)
total_batch = len(loader)
print(f'total batch : {total_batch}')
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = CNN().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)이제 학습을 진행해보자.
for epoch in range(training_epochs):
avg_cost = 0
for X, Y in loader:
X = X.to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = model(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost/total_batch
print(f'{epoch+1} : cost = {avg_cost}')위에서 hypothesis = model(X) 구문을 보자.
이전에 모델 인스턴스의 인자에 데이터를 넣으면 forward 메소드가 자동으로 동작하기 때문에 우리가 직접 forward 메소드를 호출할 필요는 없다고 했다.
model(X)가 실행되면 forward 메소드에 의해 데이터가 정의되어있는 층들을 지나게 되고 최종적으로 예측 값을 받게 된다.
마지막으로 테스트를 해보자.
테스트 할 때는 가중치를 갱신할 필요가 없다.
with torch.no_grad():
X_test = mnist_test.test_data.view(len(mnist_test), 1, 28, 28).float().to(device)
Y_test = mnist_test.test_labels.to(device)
prediction = model(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print('Accuracy:', accuracy.item())나는 98퍼센트의 정확도가 나왔다.
이번 포스팅에서는 CNN의 개념 및 특성과 간단 사용방법을 알아보았다.
다음 포스팅에서 웹 캠과 연동하여 손글씨 숫자를 인식하는 방법을 알아보겠다.
'공부 > AI' 카테고리의 다른 글
| [LangChain] LangChain 개념 및 사용법 (0) | 2023.10.18 |
|---|---|
| [PyTorch] 긍정 리뷰, 부정 리뷰 분류하기 (3) - 모델 변경 (GRU) (0) | 2023.09.19 |
| [PyTorch] 긍정 리뷰, 부정 리뷰 분류하기 (2) - 구현 (임베딩, RNN) (0) | 2023.09.18 |
| [PyTorch] 긍정 리뷰, 부정 리뷰 분류하기 (1) - 개념 (0) | 2023.09.15 |
| [PyTorch] MNIST로 학습한 CNN 모델로 웹 캠 손 글씨 숫자 인식하기 (2) (0) | 2023.09.10 |