https://growth-coder.tistory.com/247
[PyTorch] 긍정 리뷰, 부정 리뷰 분류하기 (1) - 개념
리뷰의 내용이 긍정적인 내용인지 부정적인 내용인지 분류를 해보려고 한다. 본격적인 구현에 앞서 이번 포스팅에서는 분류에 필요한 기본적인 용어들과 개념들에 대해서 알아보려고 한다. 토
growth-coder.tistory.com
이전 포스팅에서 기본적인 자연어 처리에 대한 개념을 공부했다.
이번 포스팅에서는 본격적으로 영화 리뷰에 대한 긍정, 부정 평가 학습을 해보자.
라이브러리
from torch.utils.data import Dataset, DataLoader
from torchtext.vocab import build_vocab_from_iterator
from torch.nn.utils.rnn import pad_sequence
import torch.nn as nn
import torch.nn.functional as F
from konlpy.tag import Mecab # Mecab 설치했다면 Mecab 사용
from konlpy.tag import Okt # Mecab 설치가 어렵다면 Okt 사용
import pandas as pd
import torch데이터 셋 만들기
먼저 데이터 셋을 만들어보자.
torchtext.datasets에 존재하는 여러 데이터 셋을 사용해도 되지만 이번에는 직접 txt 파일로부터 커스텀 데이터 셋을 만들어보려고 한다.
train과 test 데이터를 다운로드 하자. 데이터의 형태는 아래와 같다.
import urllib.request
import pandas as pd
# 데이터 다운로드
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt", filename="ratings_train.txt")
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt", filename="ratings_test.txt")
# 데이터프레임으로 읽음
train_df = pd.read_table('ratings_train.txt')
test_df = pd.read_table('ratings_test.txt')
이 중 필요한 필드는 document와 label이다.
이 document와 label 데이터를 연산하기 쉽게 전처리를 해야 한다.
이 전처리를 도와주는 도구가 torchtext이다.
torchtext를 사용하면 토큰화, 임베딩, 단어 사전 등등 전처리에 필요한 도구들을 편리하게 제공해준다.
기존에는 torchtext.legacy.data의 Field를 사용해서 docuoment와 label을 분리할 수 있었는데 파이토치 최신 버전에서는 legacy가 삭제되어 Field를 사용할 수가 없다.
torchtext 버전을 낮춰서 Field를 사용해도 되지만 이번에는 직접 커스텀 데이터 셋을 만들어보려고 한다.
class CustomDataset(Dataset):
def __init__(self, filename):
# 데이터프레임으로 읽고 빈 칸은 ''로 채운다.
data_df = pd.read_table(filename).fillna('')
# document 열을 읽어온다.
x_data = data_df['document'].values
self.x_data = x_data
# label열을 읽어온다.
self.y_data = data_df['label'].values
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
x = self.x_data[idx]
y = self.y_data[idx]
return y, xCustomDataset 인스턴스를 생성할 때 인자로 파일 이름을 넣어주면 document와 label열을 읽어온다.
참고로 document 열 중 결측값이 존재하기 때문에 그대로 불러와서 연산을 하면 오류가 날 수 있다.
fillna를 통해 결측값을 전부 ''로 바꿔준다.
이제 훈련과 테스트 데이터 셋을 생성하자.
train_iter = CustomDataset("ratings_train.txt")
eval_iter = CustomDataset("ratings_test.txt")토크나이저
우선 토큰화를 위한 한국어 형태소 분석기는 Mecab을 사용하자.
자신의 목적에 맞게끔 적절한 형태소 분석기를 사용하는 것이 좋다.
이번 포스팅은 기초적인 텍스트 분류에 대한 포스팅이므로 속도가 빠른 Mecab을 선택했다.
Mecab은 윈도우를 지원하지는 않으나 아래 링크를 바탕으로 설치하면 사용할 수 있다.
(윈도우 기준 Mecab 설치)
https://velog.io/@wkfwktka/%EC%9C%88%EB%8F%84%EC%9A%B0%EC%97%90-Mecab-%EC%84%A4%EC%B9%98Python
윈도우에 Mecab 설치(Python)
윈도우에 Mecab 설치 및 기본 사용법
velog.io
Mecab 사용법
from konlpy.tag import Mecab
tokenizer = Mecab()
print(tokenizer.morphs('안녕하세요 좋은 아침입니다'))결과
['안녕', '하', '세요', '좋', '은', '아침', '입니다']
Mecab 설치가 어렵다면 느리긴 하지만 다른 형태소 분서기를 사용해도 좋다.
한 번 Okt도 사용해보자.
Okt 사용법
from konlpy.tag import Okt
tokenizer = Okt()
print(tokenizer.morphs('안녕하세요 좋은 아침입니다'))결과
['안녕하세요', '좋은', '아침', '입니다']
단어 사전 만들기
토크나이저를 통해 단어 사전을 만들어보자.
토큰화를 진행해주는 yield_tokens 메소드를 만들자.
def yield_tokens(data_iter):
for _, x in data_iter:
yield tokenizer.morphs(x)단어 사전을 만들 때는 build_vocab_from_iterator를 사용하면 된다.
specials 인자를 통해 unkown 토큰과 padding 토큰을 지정해준다.
# 단어 사전 생성
# unknown 토큰과 padding 토큰 추가
vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>", "<pad>"])
# 단어 사전이 없으면 <unk> 토큰 사용
vocab.set_default_index(vocab["<unk>"])텍스트 전처리
학습을 할 때는 DataLoader를 사용할건데 DataLoader로 데이터 셋을 불러올 때 텍스트를 토큰화 처리 후 정수로 바꿔주는 전처리 함수를 만들자.
# 텍스트 처리 파이프라인
text_pipeline = lambda x : vocab(tokenizer.morphs(x))
label_pipeline = lambda x : int(x)
def collate_batch(batch):
label_list, text_list = [], []
for (label, text) in batch:
# label 파이프라인
label_list.append(label_pipeline(label))
# 토큰화 진행 후 정수 인덱스로 변경
processed_text = torch.tensor(text_pipeline(text), dtype=torch.int64)
text_list.append(processed_text)
# label list 텐서로 변경
label_list = torch.tensor(label_list, dtype=torch.int64)
# 문장의 길이가 전부 다르기 때문에 padding을 추가하여 전부 동일하게 맞춤
text_list = pad_sequence(text_list, batch_first=True, padding_value=1)
return label_list, text_list위에서 pad_sequence를 통해 길이를 전부 맞춰주는 모습을 볼 수 있다.
문장의 길이마다 토큰의 개수가 전부 다르기 때문에 이를 맞춰주는 것이다.
그리고 단어 사전을 생성할 때 specials에 unkown과 padding 토큰을 넣어주었다.
인덱스 0이 unkown이고 인덱스 1이 padding이기 때문에 padding_value에 1을 넣어준 것이다.
한 번 데이터 로더도 만들어보자.
위에서 train_iter라는 데이터 셋을 불러왔는데 이를 통해 데이터 로더를 만들어보자.
train_dataloader = DataLoader(train_iter, batch_size=batch_size, shuffle=True, collate_fn=collate_batch, drop_last=True)
collate_batch 함수는 collate_fn 인자로 넣어주면 된다.
하이퍼 파라미터
학습을 진행하기 전에 하이퍼 파라미터를 지정하자. 이 값들은 필요에 따라 적절히 변경해도 좋다.
# 하이퍼 파라미터
vocab_size = len(vocab)
n_classes = 2
learning_late = 0.001
batch_size = 64
epochs = 10
hidden_dim = 256
embed_dim = 128
모델
모델은 임베딩과 RNN을 거친다.
RNN의 경우 아래 그림과 같이 단순한 구조를 사용했다.
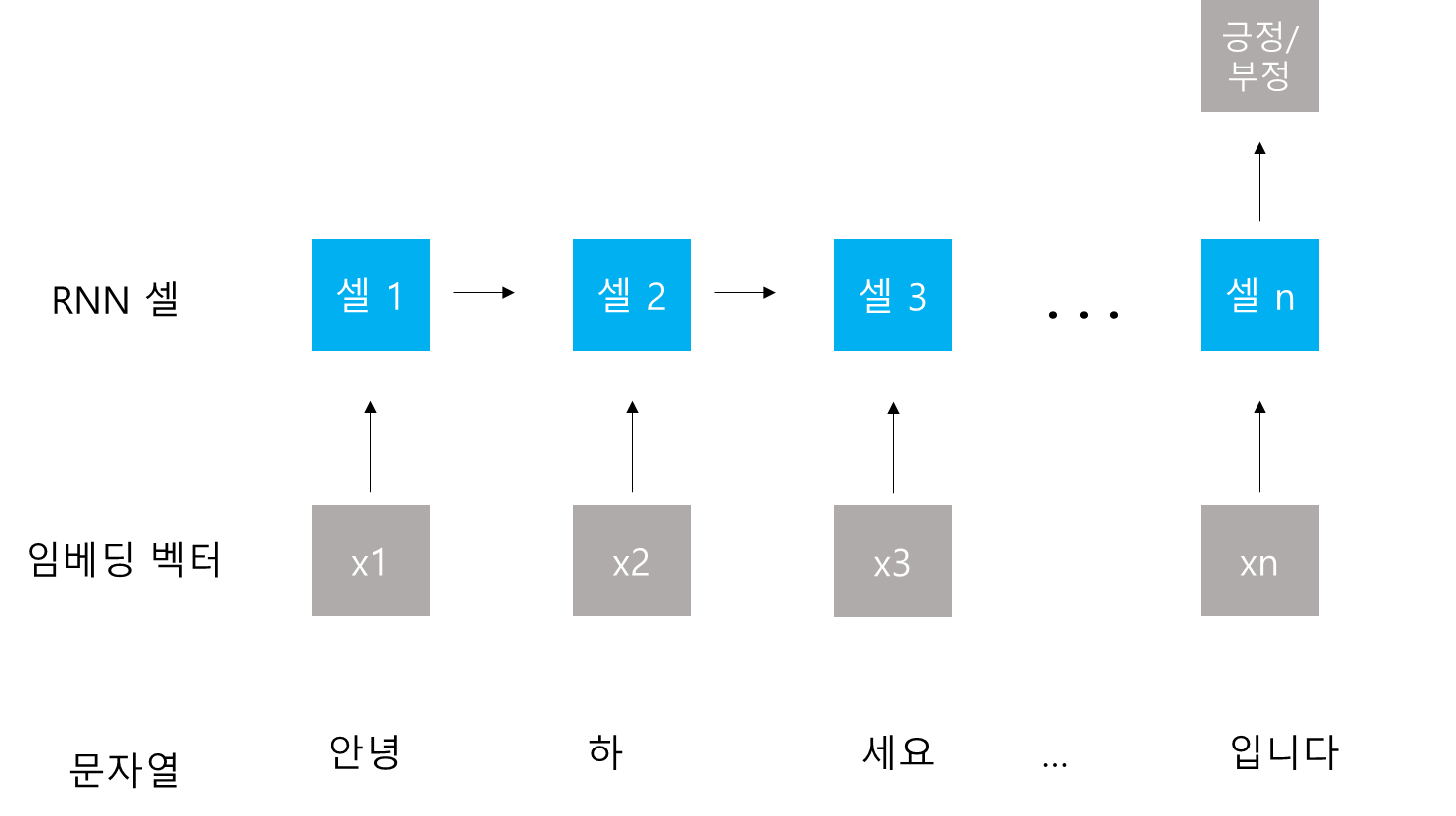
class Model(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, n_classes, batch_first=True):
super(Model, self).__init__()
# 임베딩
self.embedding_layer = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=embed_dim,
padding_idx=1
)
# RNN
self.rnn_layer = nn.RNN(
embed_dim,
hidden_dim, # 입력 차원, 은닉 상태의 크기 정의
batch_first=batch_first
)
# 마지막은 클래스의 개수로 변환
# 그렇게 해야 클래스 분류를 진행할 수 있음\
self.linear = nn.Linear(hidden_dim, n_classes) # 출력은 원-핫 벡터의 크기를 가져야함. 또는 단어 집합의 크기만큼 가져야함.
def forward(self, x):
# (배치 크기, 시퀀스 길이) => (배치 크기, 시퀀스 길이, 임베딩 차원)
x = self.embedding_layer(x)
# (배치 크기, 시퀀스 길이, 임베딩 차원) => output (배치 크기, 시퀀스 길이, 은닉층 크기), hidden (1, 배치 크기, 은닉층 크기)
output, hidden = self.rnn_layer(x)
# (배치 크기, 시퀀스 길이, 은닉 상태 크기) => (배치 크기, 은닉 상태 크기)
output = output[:, -1, :]
# (배치 크기, 은닉 상태 크기) => (배치 크기, 클래스 크기)
output = self.linear(output)
return outputtrain, evaluate 함수
모델을 사용해서 학습을 해보자.
def train(model, optimizer, train_iter):
model.train()
for i, (y, x) in enumerate(train_iter):
y, x = y.to(device), x.to(device),
optimizer.zero_grad()
hypothesis = model(x)
loss = F.cross_entropy(hypothesis, y)
loss.backward()
optimizer.step()
if (i+1)%100==0:
print(f'{i+1}번 반복. loss : {loss.sum().item()}')def evaluate(model, val_iter):
model.eval()
corrects, total_loss = 0, 0
for y, x in val_iter:
y, x = y.to(device), x.to(device),
hypothesis = model(x)
loss = F.cross_entropy(hypothesis, y)
total_loss += loss.item()
corrects += (hypothesis.max(dim=1)[1]==y).sum()
size = len(val_iter)
avg_loss = total_loss/size
acc = (corrects/(size*batch_size))*100
return avg_loss, acc이제 모델, 옵티마이저, 데이터 로더를 생성하고 원하는 epoch만큼 학습을 해보자.
# 모델 생성
model = Model(vocab_size, embed_dim, hidden_dim, n_classes, batch_first=True).to(device)
# 옵티마이저 생성
optimizer = torch.optim.Adam(model.parameters(), lr=learning_late)
# 데이터 로더 생성
train_dataloader = DataLoader(train_iter, batch_size=batch_size, shuffle=True, collate_fn=collate_batch, drop_last=True)
eval_dataloader = DataLoader(eval_iter, batch_size=batch_size, shuffle=True, collate_fn=collate_batch, drop_last=True)
# 학습 시작
for i in range(1, epochs+1):
train(model, optimizer, train_dataloader)
# 평가 시작
avg_loss, acc = evaluate(model, eval_dataloader)
print(f'[{i}/{epochs}] 평균 loss : {avg_loss} 정학도 : {acc}')모델의 구조가 굉장히 단순하기 때문에 성능이 좋지는 않다.
정확도가 약 50%정도 나오고 있다.
다음 포스팅에서는 모델에 다른 층들을 추가해서 정확도를 높여보자.
최종 코드
from torch.utils.data import Dataset, DataLoader
from torchtext.vocab import build_vocab_from_iterator
from torch.nn.utils.rnn import pad_sequence
import torch.nn as nn
import torch.nn.functional as F
from konlpy.tag import Okt
import pandas as pd
import torch
class Model(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, n_classes, batch_first=True):
super(Model, self).__init__()
# 임베딩
self.embedding_layer = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=embed_dim,
padding_idx=1
)
# RNN
self.rnn_layer = nn.RNN(
embed_dim,
hidden_dim, # 입력 차원, 은닉 상태의 크기 정의
batch_first=batch_first
)
# 마지막은 클래스의 개수로 변환
# 그렇게 해야 클래스 분류를 진행할 수 있음\
self.linear = nn.Linear(hidden_dim, n_classes) # 출력은 원-핫 벡터의 크기를 가져야함. 또는 단어 집합의 크기만큼 가져야함.
def forward(self, x):
# (배치 크기, 시퀀스 길이) => (배치 크기, 시퀀스 길이, 임베딩 차원)
x = self.embedding_layer(x)
# (배치 크기, 시퀀스 길이, 임베딩 차원) => output (배치 크기, 시퀀스 길이, 은닉층 크기), hidden (1, 배치 크기, 은닉층 크기)
output, hidden = self.rnn_layer(x)
# (배치 크기, 시퀀스 길이, 은닉층 크기) => (배치 크기, 은닉층 크기)
output = output[:, -1, :]
# (배치 크기, 은닉층 크기) => (배치 크기, 클래스 크기)
output = self.linear(output)
return output
class CustomDataset(Dataset):
def __init__(self, filename):
data_df = pd.read_table(filename).fillna('')
x_data = data_df['document'].values
self.x_data = x_data
self.y_data = data_df['label'].values
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
x = self.x_data[idx]
y = self.y_data[idx]
return y, x
# tokenizer = Mecab(dicpath="C:/mecab/mecab-ko-dic")
tokenizer = Okt()
def yield_tokens(data_iter):
for _, x in data_iter:
yield tokenizer.morphs(x)
train_iter = CustomDataset("ratings_train.txt")
eval_iter = CustomDataset("ratings_test.txt")
# 단어 사전 생성
# unknown 토큰과 padding 토큰 추가
vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>", "<pad>"])
# 단어 사전이 없으면 <unk> 토큰 사용
vocab.set_default_index(vocab["<unk>"])
# 텍스트 처리 파이프라인
text_pipeline = lambda x : vocab(tokenizer.morphs(x))
label_pipeline = lambda x : int(x)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)
def collate_batch(batch):
label_list, text_list = [], []
for (label, text) in batch:
# label 파이프라인
label_list.append(label_pipeline(label))
# 토큰화 진행 후 정수 인덱스로 변경
processed_text = torch.tensor(text_pipeline(text), dtype=torch.int64)
text_list.append(processed_text)
# label list 텐서로 변경
label_list = torch.tensor(label_list, dtype=torch.int64)
# 문장의 길이가 전부 다르기 때문에 padding을 추가하여 전부 동일하게 맞춤
text_list = pad_sequence(text_list, batch_first=True, padding_value=1)
return label_list, text_list
# 하이퍼 파라미터
vocab_size = len(vocab)
n_classes = 2
learning_late = 0.001
batch_size = 64
epochs = 10
hidden_dim = 256
embed_dim = 128
def train(model, optimizer, train_iter):
model.train()
for i, (y, x) in enumerate(train_iter):
y, x = y.to(device), x.to(device),
optimizer.zero_grad()
hypothesis = model(x)
loss = F.cross_entropy(hypothesis, y)
loss.backward()
optimizer.step()
if (i+1)%100==0:
print(f'{i+1}번 반복. loss : {loss.sum().item()}')
def evaluate(model, val_iter):
model.eval()
corrects, total_loss = 0, 0
for y, x in val_iter:
y, x = y.to(device), x.to(device),
hypothesis = model(x)
loss = F.cross_entropy(hypothesis, y)
total_loss += loss.item()
corrects += (hypothesis.max(dim=1)[1]==y).sum()
size = len(val_iter)
avg_loss = total_loss/size
acc = (corrects/(size*batch_size))*100
return avg_loss, acc
# 모델 생성
model = Model(vocab_size, embed_dim, hidden_dim, n_classes, batch_first=True).to(device)
# 옵티마이저 생성
optimizer = torch.optim.Adam(model.parameters(), lr=learning_late)
# 데이터 로더 생성
train_dataloader = DataLoader(train_iter, batch_size=batch_size, shuffle=True, collate_fn=collate_batch, drop_last=True)
eval_dataloader = DataLoader(eval_iter, batch_size=batch_size, shuffle=True, collate_fn=collate_batch, drop_last=True)
# 학습 시작
for i in range(1, epochs+1):
train(model, optimizer, train_dataloader)
# 평가 시작
avg_loss, acc = evaluate(model, eval_dataloader)
print(f'[{i}/{epochs}] 평균 loss : {avg_loss} 정학도 : {acc}')
참고
12-02 IMDB 리뷰 감성 분류하기(IMDB Movie Review Sentiment Analysis)
머신 러닝에서 텍스트 분류를 연습하기 위해 자주 사용하는 데이터가 있습니다. 바로 영화 사이트 IMDB의 리뷰 데이터입니다. 이 데이터는 리뷰에 대한 텍스트와 해당 리뷰가 긍정인…
wikidocs.net
Migrate torchtext from the legacy API to the new API
Run, share, and edit Python notebooks
colab.research.google.com
torchtext 라이브러리로 텍스트 분류하기 — 파이토치 한국어 튜토리얼 (PyTorch tutorials in Korean)
torchtext 라이브러리로 텍스트 분류하기
번역: 김강민, 김진현 이 튜토리얼에서는 torchtext 라이브러리를 사용하여 어떻게 텍스트 분류 분석을 위한 데이터셋을 만드는지를 살펴보겠습니다. 다음과 같은 내용들을 알게 됩니다: 반복자(it
tutorials.pytorch.kr
'공부 > AI' 카테고리의 다른 글
| [LangChain] LangChain 개념 및 사용법 (0) | 2023.10.18 |
|---|---|
| [PyTorch] 긍정 리뷰, 부정 리뷰 분류하기 (3) - 모델 변경 (GRU) (0) | 2023.09.19 |
| [PyTorch] 긍정 리뷰, 부정 리뷰 분류하기 (1) - 개념 (0) | 2023.09.15 |
| [PyTorch] MNIST로 학습한 CNN 모델로 웹 캠 손 글씨 숫자 인식하기 (2) (0) | 2023.09.10 |
| [PyTorch] MNIST로 학습한 CNN 모델로 웹 캠 손 글씨 숫자 인식하기 (1) (0) | 2023.09.09 |