저번 포스팅에서 기본적인 LangChain 동작 방식과 여러 옵션들을 알아보았다.
이번에는 Retrieval을 통해서 원하는 document에 질의를 한 후 원하는 답변을 얻어보려고 한다.
RAG(Retrieval Augmented Generation)
RAG는 검색 증강 생성으로 모델이 답변을 생성하는데 도움을 줄 수 있다.
LLM 기초 사용법을 알아보면서 prompt를 생성할 때 배경 context라던가 역할을 부여해주면서 더욱 퀄리티 있는 답변을 얻을 수 있었다.
RAG 역시 이와 비슷한 역할을 하는데 모델의 답변을 강화하기 위해서 외부에 있는 데이터에서 검색을 하는 것이다.
추가적인 정보를 제공해주기 때문에 정확도 높은 답변을 얻을 수 있는 것이다.
다음은 검색 과정을 나타낸 그림이다.
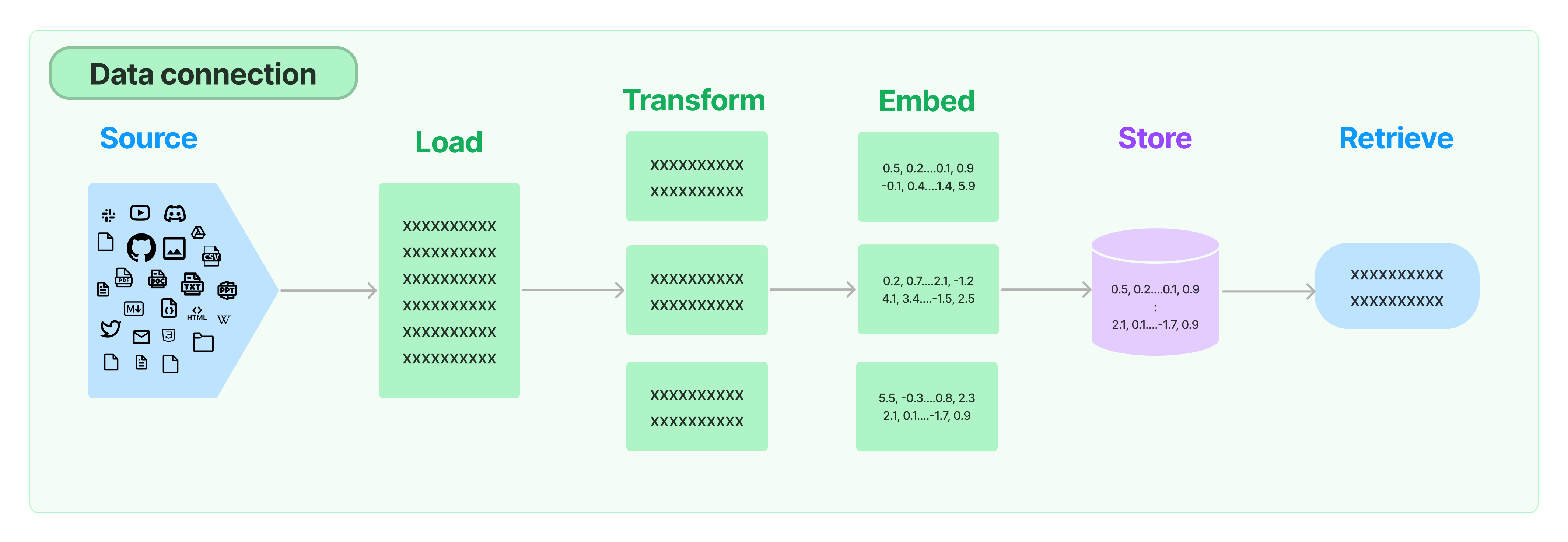
Document Loader
document loader는 다양한 source로부터 document를 가져온다.
text, pdf, csv, html 등등... 다양한 dcument들을 가져올 수 있다.
한번 pdf 파일을 document loader를 통해서 온라인에서 가져와보자.
사용할 pdf 파일 주소는 아래와 같고 self RAG에 관한 내용이다.
https://arxiv.org/pdf/2310.11511
from langchain.document_loaders import OnlinePDFLoader
loader = OnlinePDFLoader("https://arxiv.org/pdf/2310.11511.pdf")
pages = loader.load_and_split()
print(pages[0])출력
page_content='3 2 0 2\n\nt c O 7 1\n\n] L C . s c [\n\n1 v 1 1 5 1 1 . 0 1 3 2 : v i X r a\n\nPreprint.\n\nSELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION\n\nAkari Asai†, Zeqiu Wu†, Yizhong Wang†§, Avirup Sil‡, Hannaneh Hajishirzi†§ †University of Washington §Allen Institute for AI {akari,zeqiuwu,yizhongw,hannaneh}@cs.washington.edu, avi@us.ibm.com\n\n‡IBM Research AI\n\nABSTRACT\n\nDespite their remarkable capabilities, large language models (LLMs) often produce responses containing factual inaccuracies due to their sole reliance on the paramet- ric knowledge they encapsulate. Retrieval-Augmented Generation (RAG), an ad hoc approach that augments LMs with retrieval of relevant knowledge, decreases such issues. However, indiscriminately retrieving and incorporating a fixed number of retrieved passages, regardless of whether retrieval is necessary, or passages are relevant, diminishes LM versatility or can lead to unhelpful response generation. We introduce a new framework called Self-Reflective Retrieval-Augmented Gen- eration (SELF-RAG) that enhances an LM’s quality and factuality through retrieval and self-reflection. Our framework trains a single arbitrary LM that adaptively retrieves passages on-demand, and generates and reflects on retrieved passages and its own generations using special tokens, called reflection tokens. Generating reflection tokens makes the LM controllable during the inference phase, enabling it to tailor its behavior to diverse task requirements. Experiments show that SELF- RAG (7B and 13B parameters) significantly outperforms state-of-the-art LLMs and retrieval-augmented models on a diverse set of tasks. Specifically, SELF-RAG outperforms ChatGPT and retrieval-augmented Llama2-chat on Open-domain QA, reasoning and fact verification tasks, and it shows significant gains in improving factuality and citation accuracy for long-form generations relative to these models.1\n\n1\n\nINTRODUCTION' metadata={'source': 'C:\\Users\\growth\\AppData\\Local\\Temp\\tmpxs23mn38\\tmp.pdf'}

pdf 첫 번째 장의 내용을 출력하는 모습을 확인할 수 있다.
더욱 다양한 document loader는 공식문서에서 확인할 수 있다.
Transform
굉장히 긴 문서를 작은 단위로 분할해서 사용할 수 있다.
텍스트 분할기는 작은 단위로 나누고 사용자가 원하는 크기에 도달할 때까지 서로 결합 후 컨텍스트 유지를 위해 약간 겹치는 새로운 덩어리를 생성한다.
텍스트 분할기는 다음 두 가지를 정해서 사용한다.
- 텍스트 분할 방식
- 덩어리 크기 측정 방식
대표적인 텍스트 분할기인 RecursiveCharacterTextSplitter를 사용해보자.
먼저 텍스트 분할기를 정의한다.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 100, # 원하는 덩어리 사이즈
chunk_overlap = 20, # 겹치는 정도 (컨텍스트 유지 목적)
length_function = len, # 길이 측정 함수
add_start_index = True # 원본의 덩어리 시작 위치를 보여줄지 여부
)그리고 아까 pdf 파일을 document로 불러와서 분할 후 10번째와 11번째를 가져와보자.
from langchain.document_loaders import OnlinePDFLoader
loader = OnlinePDFLoader("https://arxiv.org/pdf/2310.11511.pdf")
data = loader.load()
texts = text_splitter.split_documents(data)
print(texts[10])
print(texts[11])출력
page_content='decreases such issues. However, indiscriminately retrieving and incorporating a fixed number of' metadata={'source': 'C:\\Users\\growth\\AppData\\Local\\Temp\\tmpxlhhegjd\\tmp.pdf', 'start_index': 697}
page_content='a fixed number of retrieved passages, regardless of whether retrieval is necessary, or passages are' metadata={'source': 'C:\\Users\\growth\\AppData\\Local\\Temp\\tmpxlhhegjd\\tmp.pdf', 'start_index': 775}
출력에서 볼 수 있듯이 우리가 텍스트 분할기에 설정을 한 대로 분할을 한 모습을 확인할 수 있다.
컨텍스트 유지를 위해 서로 겹치는 부분이 존재하고 원본 문서의 어디에 이 문장이 있는지도 보여주고 있다.
더욱 다양한 분할기는 공식문서에서 확인할 수 있다.
Embed
LangChain의 Embeddings 클래스는 문서를 임베딩하는 메소드와 질의를 임베딩하는 메소드 두 가지가 있다.
간혹 문서와 질의를 임베딩하는 방식을 다르게 사용하는 경우가 있어서 두 메소드가 존재한다고 한다.
이를 사용하기 위해서 open api key를 환경 변수로 등록하자. (아래 링크 참고)
https://growth-coder.tistory.com/253
[PyTorch/LangChain] LangChain 개념 및 사용법
LangChain LangChain은 LLM(Large Language Model)을 사용하여 애플리케이션 생성을 쉽게 할 수 있도록 도와주는 프레임워크이다. 우선 Model input output은 다음과 같다. 순서대로 살펴보자. Format 이 단계에서는
growth-coder.tistory.com
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings()
print(texts[3])
documents = [
"hello",
"world"
]
embeddings = embeddings_model.embed_documents(documents)
query = "hello!"
embedded_query = embeddings_model.embed_query(query)
print(len(embeddings), len(embeddings[0]))
print(len(embedded_query))
출력
2 1536
1536
그런데 우리는 직접 임베딩 메소드를 사용하지 않고 벡터 저장소를 사용하여 임베딩을 진행해보자.
벡터 저장소를 사용할 때의 과정은 다음과 같다.
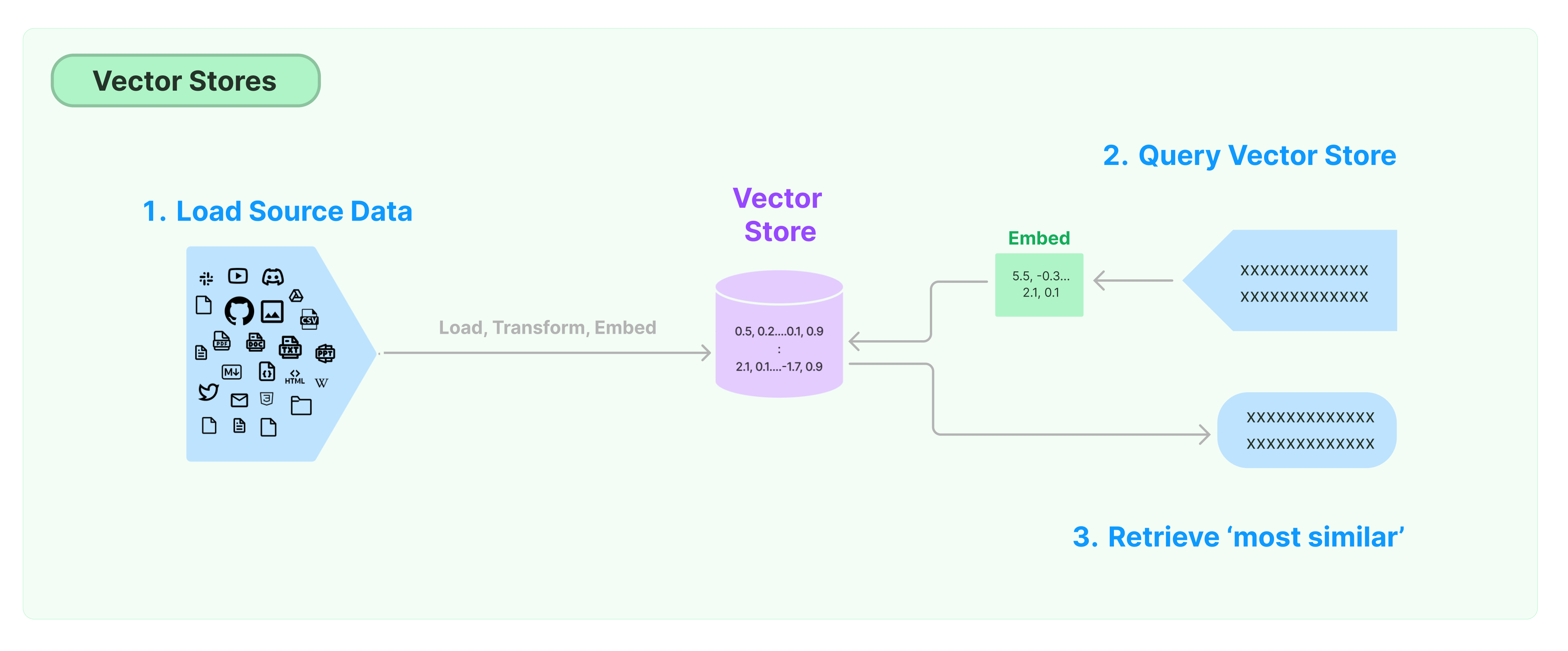
지금까지 했던 것에 이어서 document를 분할하고 from_documents 함수의 인자에 해당 document와 임베딩 모델을 인자로 넣어주자.
그리고 비슷한 쿼리를 생성해보자.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import OnlinePDFLoader
loader = OnlinePDFLoader("https://arxiv.org/pdf/2310.11511.pdf")
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 100, # 원하는 덩어리 사이즈
chunk_overlap = 20, # 겹치는 정도 (컨텍스트 유지 목적)
length_function = len, # 길이 측정 함수
add_start_index = True # 원본의 덩어리 시작 위치를 보여줄지 여부
)
data = loader.load()
texts = text_splitter.split_documents(data)
documents = text_splitter.split_documents(texts)
embedding_models = OpenAIEmbeddings()
// Chroma db 생성
db = Chroma.from_documents(documents, embedding_models)
// 쿼리 생성
query = "What is self RAG?"
// 비슷한 것 검색
docs = db.similarity_search(query)
print(docs[0])
print(docs[1])출력
page_content='Retrieval-Augmented Generation (RAG)Ours: Self-reflective Retrieval-Augmented Generation (Self-RAG)' metadata={'source': 'C:\\Users\\growth\\AppData\\Local\\Temp\\tmp9mwm4hk0\\tmp.pdf', 'start_index': 0}
page_content='Algorithm 1 SELF-RAG Inference' metadata={'source': 'C:\\Users\\growth\\AppData\\Local\\Temp\\tmp9mwm4hk0\\tmp.pdf', 'start_index': 0}
page_content를 보면 된다.
위는 String으로 검색을 했는데 벡터로도 검색이 가능하다.
쿼리를 임베딩 벡터로 만들어서 검색을 해보자.
embedded_query = embeddings_model.embed_query(query)
docs = db.similarity_search_by_vector(embedded_query)
print(docs[0])
print(docs[1])임베딩 방식이 동일하기 때문에 출력값은 똑같다.
그런데 여기서 얻은 값은 우리가 원하는 값이 아니다.
우리가 원하는 것은 chat model이 해당 document를 읽어서 사용자의 질문에 맞게 답변을 생성해주는 것이다.
그리고 지금까지 우리는 사용자가 던진 질문과 가장 유사한 문장을 가져오는 것까지 해보았다.
이제 이 가져온 문장을 chat model에게 알려주고 답변을 생성해보자.
먼저 langchain hub에서 RAG와 관련된 프롬프트를 가져온다.
from langchain import hub
from langchain.chat_models import ChatOpenAI
prompt = hub.pull("rlm/rag-prompt") # rag prompt 가져오기
print(prompt)rlm/rag-promt는 아래와 같은 형태이다.
input_variables=['question', 'context'] messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['question', 'context'], template="You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.\nQuestion: {question} \nContext: {context} \nAnswer:"))]
context에는 질문과 가장 유사한 document 내용을 넣어주고 question에는 질문을 넣어주면 된다.
LCEL로 체인을 만들어보자.
from langchain.chat_models import ChatOpenAI
chat_model = ChatOpenAI() # chat model 정의
# chain 생성
from langchain.schema import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context" : retriever | format_docs, "question" : RunnablePassthrough()}
| prompt
| chat_model
| StrOutputParser()
)
response = rag_chain.invoke("What is self RAG")
print(response)
결과
SELF-RAG stands for Self-Reflective Retrieval-Augmented Generation. It is a framework that enhances the quality and factuality of a language model (LLM) through retrieval and self-reflection, without compromising the LLM's original creativity and versatility. SELF-RAG uses retrieved passages to inform the generation process and incorporates reflection tokens to signal the need for retrieval or confirm the output's relevance, support, or completeness.
단순히 유사한 문장을 추출하는 것에 그치는게 아니라 그 정보를 이용해서 답변을 생성하는 것에 성공했다.
참고
https://python.langchain.com/docs/modules/data_connection/
Retrieval | 🦜️🔗 Langchain
Many LLM applications require user-specific data that is not part of the model's training set.
python.langchain.com
'공부 > AI' 카테고리의 다른 글
| [LangChain] Agent와 Tool 사용법 (0) | 2023.11.27 |
|---|---|
| [LangChain] Chains와 LCEL 사용법 (0) | 2023.10.27 |
| [LangChain] Few Shot Prompting, Dynamic Few Shot Prompting (1) | 2023.10.21 |
| [LangChain] Prompts, Caching, Streaming, Token Usage (0) | 2023.10.20 |
| [LangChain] LangChain 개념 및 사용법 (0) | 2023.10.18 |